
Executive Summary
This guide provides a comprehensive framework for implementing production-ready Retrieval-Augmented Generation (RAG) systems that deliver meaningful business value through improved accuracy, performance, and security.
Key Implementation Phases:
- Requirements Analysis: Define performance needs, data characteristics, and budget constraints
- Ingestion Pipeline: Build robust connectors with appropriate chunking and metadata
- Embedding & Vector Store: Select and configure vector embeddings and storage
- Retrieval Mechanism: Implement hybrid search, query transformation, and reranking
- Generation Integration: Engineer prompts, manage context windows, select appropriate models
- Optimization & Scaling: Analyze bottlenecks and implement comprehensive monitoring
Critical Implementation Considerations:
- Security & Governance: Implement row-level security, encryption, and data lineage tracking
- Evaluation: Measure both retrieval quality and generation quality with specialized metrics
- Operational Reliability: Plan for disaster recovery, versioning, and avoiding common pitfalls
- Cost Management: Understand TCO across infrastructure, API costs, and operational overhead
Implementation Strategy by Organization Size:
- Lean teams, pre-product market fit/Series A: Start with managed services and focus on core functionality
- Scaling teams with product-market fit: Implement hybrid approach with custom components in critical areas
- Regulated / high-throughput organizations: Build specialized RAG pipelines with robust security and compliance
For time-pressed readers, see the Conclusion section for a summary of the six critical dimensions to balance for successful RAG implementation.
Introduction: Why RAG Matters to Your Engineering Strategy
As AI increasingly becomes integral to enterprise applications, engineering leaders face a critical challenge: LLMs alone are insufficient for building trustworthy AI systems. Despite their impressive capabilities, Large Language Models suffer from knowledge cutoffs, hallucinations, and inability to access proprietary information.
Retrieval-Augmented Generation (RAG) has emerged as the vital architecture that addresses these limitations by grounding LLM outputs in reliable, up-to-date information sources. For engineering leaders, successful RAG implementation unlocks business-critical AI applications previously impossible due to reliability concerns.
A common misconception among technical leaders is that RAG is simply "search plus an LLM," when in reality it's a complex distributed system with subtle interactions between components. This misunderstanding is common and can lead to significant implementation challenges.
This guide provides a systematic framework for engineering leaders to navigate these complexities and build RAG systems that deliver meaningful business value.
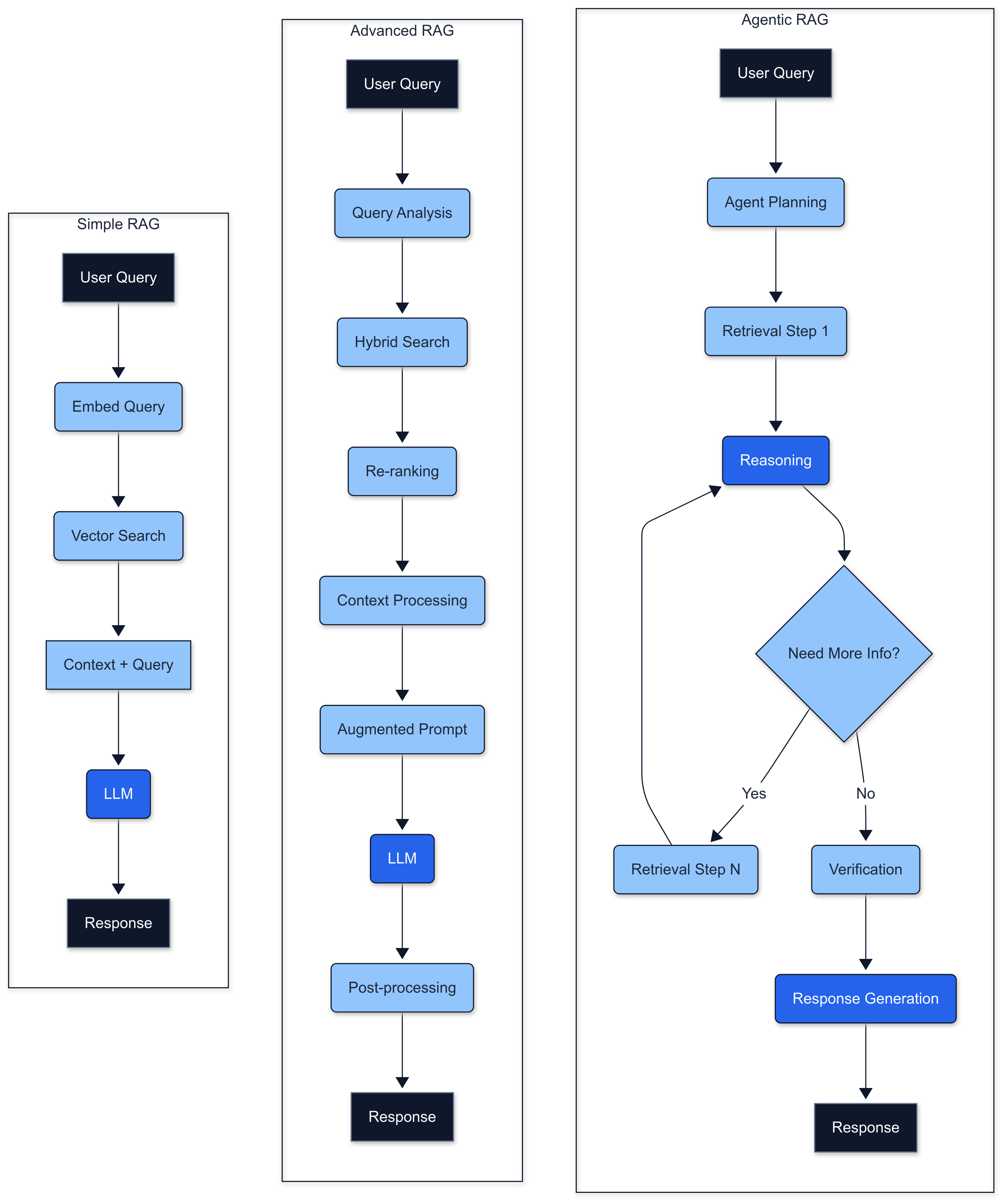
Fig 1. Comparing RAG architectural patterns: Simple, Advanced, and Agentic, each scaling in complexity and capability to meet diverse application needs.
Please note that code examples in this document are illustrative and conceptual. They focus on underlying principles and are not tied to specific vendor implementations to ensure broad applicability.
The RAG Implementation Framework
To address these challenges, I suggest a six-phase implementation framework that balances rapid experimentation with systematic optimization:
- Requirements Analysis & Architecture Planning
- Ingestion Pipeline Development
- Embedding & Vector Store Configuration
- Retrieval Mechanism Design
- Generation Component Integration
- End-to-End Optimization & Scaling
Let's examine each phase in detail.
Phase 1: Requirements Analysis & Architecture Planning
Before writing a line of code, you must clearly define your requirements across multiple dimensions:
Performance Requirements
- Latency: What's your response time budget? Interactive applications typically require <1-2 seconds total response time.
- Throughput: How many queries per second must your system handle at peak?
- Accuracy: What level of factual correctness is required? Is 95% sufficient, or do you need 99.9%?
- Freshness: How quickly must new information be reflected in responses?
Data Characteristics
- Volume: How much data needs to be indexed? (GB/TB)
- Variety: What formats and sources must be supported? (PDFs, websites, databases, APIs)
- Update Frequency: How often does the data change?
- Sensitivity: Does the data contain confidential or regulated information?
Budget Constraints
- Infrastructure Costs: What's your budget for compute, storage, and managed services?
- API Costs: If using commercial LLMs or embedding APIs, what's your per-query budget?
- Development Resources: What team size and expertise are available for implementation?
Based on these requirements, you can select an appropriate architectural approach:
Simple RAG: For smaller datasets, lower query volumes, and moderate accuracy requirements.
1User Query → Embedding → Vector Search → Context + Query → LLM → Response
2Advanced RAG: For demanding applications requiring higher precision, recall, or handling complex queries.
1User Query → Query Analysis/Rewriting → Hybrid Search (Vector + Keyword) → Re-ranking → Context Processing → Augmented Prompt Engineering → LLM → Post-processing → Response
2Agentic RAG: For complex reasoning tasks requiring multiple retrieval steps or combining multiple information sources.
1User Query → Agent Planning → Multiple Retrieval Steps → Reasoning → Verification → Response Generation
2Phase 2: Ingestion Pipeline Development
The ingestion pipeline is the foundation of your RAG system. Poor implementation here creates "technical debt" that's difficult to overcome downstream.
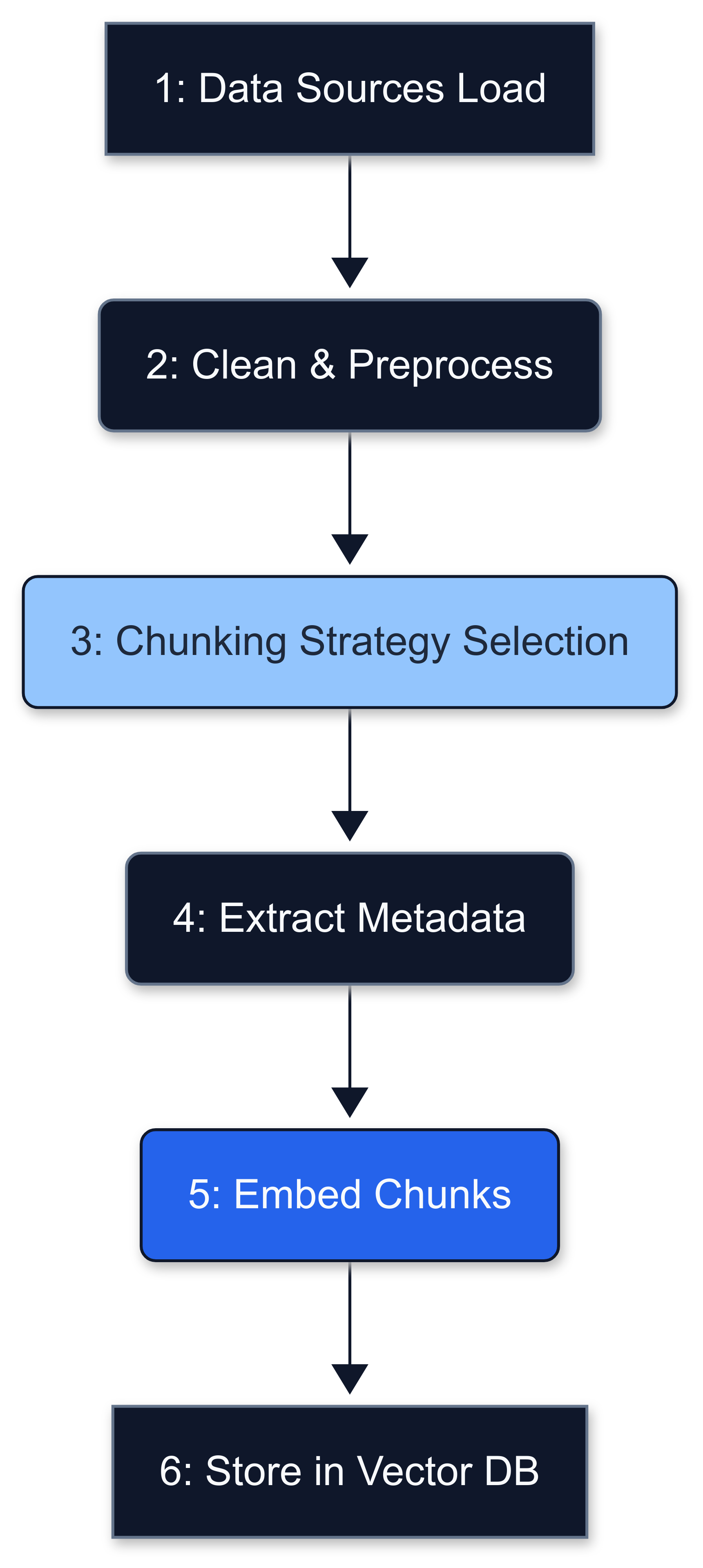
Fig 2. Overview of the RAG data ingestion pipeline, converting raw data into indexed, searchable knowledge for the LLM.
Data Loading
Start by building robust connectors to your data sources:
1# Example of a flexible document loader system
2class DocumentLoader:
3 def __init__(self, config):
4 self.config = config
5 self.loaders = {
6 'pdf': self._load_pdf,
7 'webpage': self._load_webpage,
8 'database': self._load_database
9 }
10
11 def load(self, source, source_type=None):
12 if not source_type:
13 source_type = self._detect_source_type(source)
14 return self.loaders[source_type](source)
15
16 def _load_pdf(self, source):
17 # PDF loading logic with error handling
18 # Consider OCR for scanned documents
19Data Cleaning and Preprocessing
Implement thorough cleaning to ensure high-quality inputs:
- Remove irrelevant content
- Standardize formatting and correct errors
- Filter out low-value or duplicative content
- Anonymize sensitive information if needed
Chunking Strategy Selection
Choose a chunking strategy appropriate for your content:
| Strategy | Best For | Implementation Complexity |
|---|---|---|
| Fixed-Size | Quick prototyping | Low |
| Recursive Character | General purpose | Medium |
| Content-Aware | Structured documents | Medium |
| Semantic | Complex, varied content | High |
Best Practice: Always test multiple chunking strategies with your specific data and evaluation metrics. Optimal chunk size typically varies significantly by use case and content type, with common ranges between 200-1000 tokens and 10-20% overlap.
Metadata Extraction and Enrichment
Enhance your chunks with metadata to improve retrievability and context:
1def extract_metadata(document, chunk):
2 """Extract and generate metadata for a document chunk."""
3 metadata = {
4 "source": document.source,
5 "created_at": document.created_at,
6 "chunk_position": chunk.position,
7 # Add domain-specific metadata
8 }
9
10 # Optional: LLM-based metadata generation
11 if self.config.enable_llm_metadata:
12 metadata["summary"] = self.summarizer.summarize(chunk.text)
13 metadata["entities"] = self.entity_extractor.extract(chunk.text)
14
15 return metadata
16Implementation Insight: For enterprise applications with heterogeneous data sources, implementing rich metadata extraction can significantly improve retrieval performance. It enables filtering and relevance improvements that pure vector similarity often struggles to achieve on its own.
Phase 3: Embedding & Vector Store Configuration
With your knowledge chunks prepared, the next phase focuses on transforming them into vector representations and configuring your vector storage solution.
Embedding Model Selection
Select your embedding model based on these criteria:
- Performance on domain-specific retrieval tasks
- Dimensional efficiency vs. semantic richness
- Inference speed and computational requirements
- Hosting costs (API vs. self-hosted)
For enterprise applications:
- OpenAI text-embedding-3-large (if budget permits) for highest general performance
- BGE-Large or Ember-V1 for high-performance open-source options
- BAAI/bge-m3 for long document contexts
- Hybrid approaches combining dense + sparse for highest accuracy on technical content
Implementation Insight: Fine-tuning your own embedding model on just domain-specific examples can outperform general-purpose models..
Vector Store Selection and Optimization
Choose your vector database based on your requirements:
| Vector Database | Best For | Deployment Model |
|---|---|---|
| Pinecone | Simple deployment, high reliability | Fully managed |
| Weaviate | Rich schema, hybrid search | Self-hosted or managed |
| Milvus/Zilliz | Large-scale deployments | Self-hosted or managed |
| Qdrant | Strong filtering, self-hosting | Self-hosted or managed |
| pgvector | Integration with existing Postgres | Self-hosted |
> For detailed guide with code examples on setting up metadata filtering :
Optimize your vector index configuration for your specific performance requirements:
1# Example HNSW configuration optimization for Qdrant
2client.update_collection(
3 collection_name="my_rag_collection,
4 hnsw_config=models.HnswConfigDiff(
5 m=32, # Increase the number of edges per node from the default 16 to 32
6 # Having larger M value is desirable for higher accuracy,
7 # use lower if we care more about memory usage
8 ef_construct=200, # Increase the number of neighbours from the default 100 to 200
9 #Larger the value - more accurate the search, more time required to build the index.
10 on_disk=False #Store HNSW index on disk. If set to false, the index will be stored in RAM.
11 )
12)
13
14Leadership Perspective: Many teams prematurely optimize vector storage before establishing robust evaluation frameworks. Start with managed vector databases and default configurations for initial development, then optimize based on rigorous performance testing.
Phase 4: Retrieval Mechanism Design
Your retrieval mechanism translates user queries into relevant knowledge chunks that provide context for generation.
Basic Retrieval Implementation
At minimum, implement standard similarity-based retrieval:
1def retrieve(query, top_k=5, filters=None):
2 """Basic retrieval function with filtering."""
3 query_embedding = embedding_model.embed(query)
4
5 results = vector_store.search(
6 query_vector=query_embedding,
7 limit=top_k,
8 filter=filters
9 )
10
11 return [
12 {
13 "text": result.payload["text"],
14 "metadata": result.payload["metadata"],
15 "score": result.score
16 }
17 for result in results
18 ]
19Advanced Retrieval Techniques
For higher performance, consider these enhancements:
Hybrid Search
1def hybrid_search(query, top_k=5, filters=None):
2 """Hybrid dense + sparse retrieval with fusion."""
3 # Get results from vector search
4 dense_results = vector_search(query, top_k=top_k*2, filters=filters)
5
6 # Get results from keyword search (BM25 or similar)
7 sparse_results = keyword_search(query, top_k=top_k*2, filters=filters)
8
9 # Apply Reciprocal Rank Fusion
10 fused_results = rank_fusion(dense_results, sparse_results, k=60)
11
12 return fused_results[:top_k]
13Query Transformation
1def enhanced_retrieval(original_query, top_k=5):
2 """LLM-powered query transformation and retrieval."""
3 # Generate multiple query variations
4 variations = query_transformer.generate_variations(original_query)
5
6 # Retrieve for each variation
7 all_results = []
8 for query in variations:
9 results = retrieve(query, top_k=top_k//len(variations))
10 all_results.extend(results)
11
12 # Deduplicate and rerank
13 return reranker.rerank(original_query, deduplicate(all_results))
14Re-ranking
Implement a re-ranking step to improve precision:
1def rerank(query, initial_results, top_n=5):
2 """Rerank initial retrieval results using a cross-encoder."""
3 pairs = [(query, result["text"]) for result in initial_results]
4
5 # Use a cross-encoder model for more accurate relevance scoring
6 rerank_scores = cross_encoder_model.predict(pairs)
7
8 # Combine with initial results
9 for i, result in enumerate(initial_results):
10 result["rerank_score"] = rerank_scores[i]
11
12 # Sort by rerank score and return top_n
13 reranked_results = sorted(
14 initial_results,
15 key=lambda x: x["rerank_score"],
16 reverse=True
17 )
18
19 return reranked_results[:top_n]
20Implementation Insight: Query transformation and reranking techniques can deliver substantial improvements for complex retrieval tasks. These approaches are particularly valuable when dealing with domain-specific terminology or when users phrase questions differently from how information is stored in documents.
Phase 5: Generation Component Integration
With relevant context retrieved, you now need to integrate it with your LLM to produce accurate, grounded responses.
Context Preparation and Prompt Engineering
Proper prompt engineering is crucial for effective RAG:
1def construct_prompt(query, context_chunks, system_message):
2 """Construct a well-structured RAG prompt."""
3 # Format retrieved chunks with metadata
4 formatted_context = "\n\n".join([
5 f"Source: {chunk['metadata']['source']}\n" +
6 f"Date: {chunk['metadata']['date']}\n" +
7 f"Content: {chunk['text']}"
8 for chunk in context_chunks
9 ])
10
11 # Create the augmented prompt
12 prompt = f"""
13 {system_message}
14
15 The user has asked: "{query}"
16
17 Here is information to help answer the query:
18
19 {formatted_context}
20
21 Instructions:
22 1. Answer the query based ONLY on the information provided above.
23 2. If the information is insufficient, state what's missing rather than guessing.
24 3. Always cite your sources from the provided context.
25 4. Format your answer in a clear, concise manner.
26
27 Answer:
28 """
29
30 return prompt
31Context Window Management
Handle context window limitations with techniques like:
- Context pruning: Remove less relevant chunks when approaching limits
- Chunk prioritization: Place most relevant chunks at beginning/end to combat "lost in the middle" effects
- Compression: Summarize context chunks to fit more information
1def manage_context_window(chunks, query, max_tokens, model):
2 """Manage context to fit within token limits."""
3 # Calculate tokens in system message, query, and instructions
4 fixed_tokens = count_tokens(SYSTEM_MESSAGE + query + INSTRUCTIONS, model)
5 available_tokens = max_tokens - fixed_tokens - RESPONSE_BUFFER
6
7 # If we're within limits, use all chunks
8 if sum(count_tokens(chunk["text"], model) for chunk in chunks) <= available_tokens:
9 return chunks
10
11 # Otherwise, we need to optimize
12 # Option 1: Prioritize highest scoring chunks
13 prioritized = sorted(chunks, key=lambda x: x["score"], reverse=True)
14
15 # Option 2: Compress chunks
16 compressed_chunks = []
17 for chunk in prioritized:
18 if chunk["score"] > HIGH_RELEVANCE_THRESHOLD:
19 # Keep high relevance chunks intact
20 compressed_chunks.append(chunk)
21 else:
22 # Summarize less relevant chunks
23 compressed = summarizer.summarize(chunk["text"])
24 compressed_chunks.append({**chunk, "text": compressed})
25
26 # Return as many chunks as will fit
27 return fit_chunks_to_token_limit(compressed_chunks, available_tokens, model)
28Practical Insight: In production RAG systems, context window management often becomes a critical issue. Consider implementing basic window management (pruning/prioritization) early in development, then adding more sophisticated techniques like compression as your system matures.
Model Selection and Configuration
Choose your generation model based on accuracy requirements, latency constraints, and cost considerations:
| MODEL CLASS | GENERAL CAPABILITIES | COMMON PROS | COMMON CONS | BEST FOR | EXAMPLES (Illustrative, as of mid-2025) |
|---|---|---|---|---|---|
| **1. Frontier Proprietary Models** | Highest accuracy, leading-edge reasoning, multimodal | Top performance, advanced features, reliable APIs, strong safety/support | Highest cost, latency, vendor lock-in, data privacy concerns (API) | High-value, complex tasks, R&D, advanced content/agentic workflows | OpenAI GPT-4 series, Anthropic Claude 3 series (Opus), Google Gemini Advanced/Ultra series |
| **2. High-Performance Open-Source Models** | Near-frontier performance, good context, customizable | Cost-effective (self-hosted), data control, high customization, transparency | Infrastructure/expertise needed, can lag slightly on newest features, self-managed safety | Custom solutions, research, fine-tuning critical, cost-sensitive scale | Meta Llama series, Mistral Large/Next, other leading open-weight models |
| **3. Efficient/Smaller Open-Source Models** | Good for size, fast inference, task-specific tuning | Low hosting cost, speed, on-device potential, accessible | Lower general accuracy/reasoning than larger models, limited context sometimes | Specific tasks (summarization, simple Q&A), edge AI, high-volume/low-latency, educational use | Mistral Small/Medium, Gemma, Phi series |
| **4. Specialized Proprietary Cloud Models** | Optimized for specific tasks/cloud ecosystems, balanced | Easy cloud integration, managed service, reliable for supported tasks | Vendor lock-in, less generalizable than frontier, potential API costs | Enterprise document processing, industry-specific Q&A within a cloud ecosystem | Cloud provider-specific AI services (AWS, Azure, GCP), cost/performance optimized API tiers |
| **5. Task-Specific Fine-Tuned Models** | Excels at narrow pre-defined tasks | High accuracy on target task, reduced domain-specific hallucination | Poor out-of-domain performance, fine-tuning effort/cost, data needs | Highly specific, repetitive NLP tasks (e.g., specific code gen, medical QA, legal clause extraction) | BloombergGPT, Med-PaLM, Code Llama, custom fine-tunes |
Phase 6: End-to-End Optimization & Scaling
With your components integrated, focus on end-to-end optimization to maximize performance:
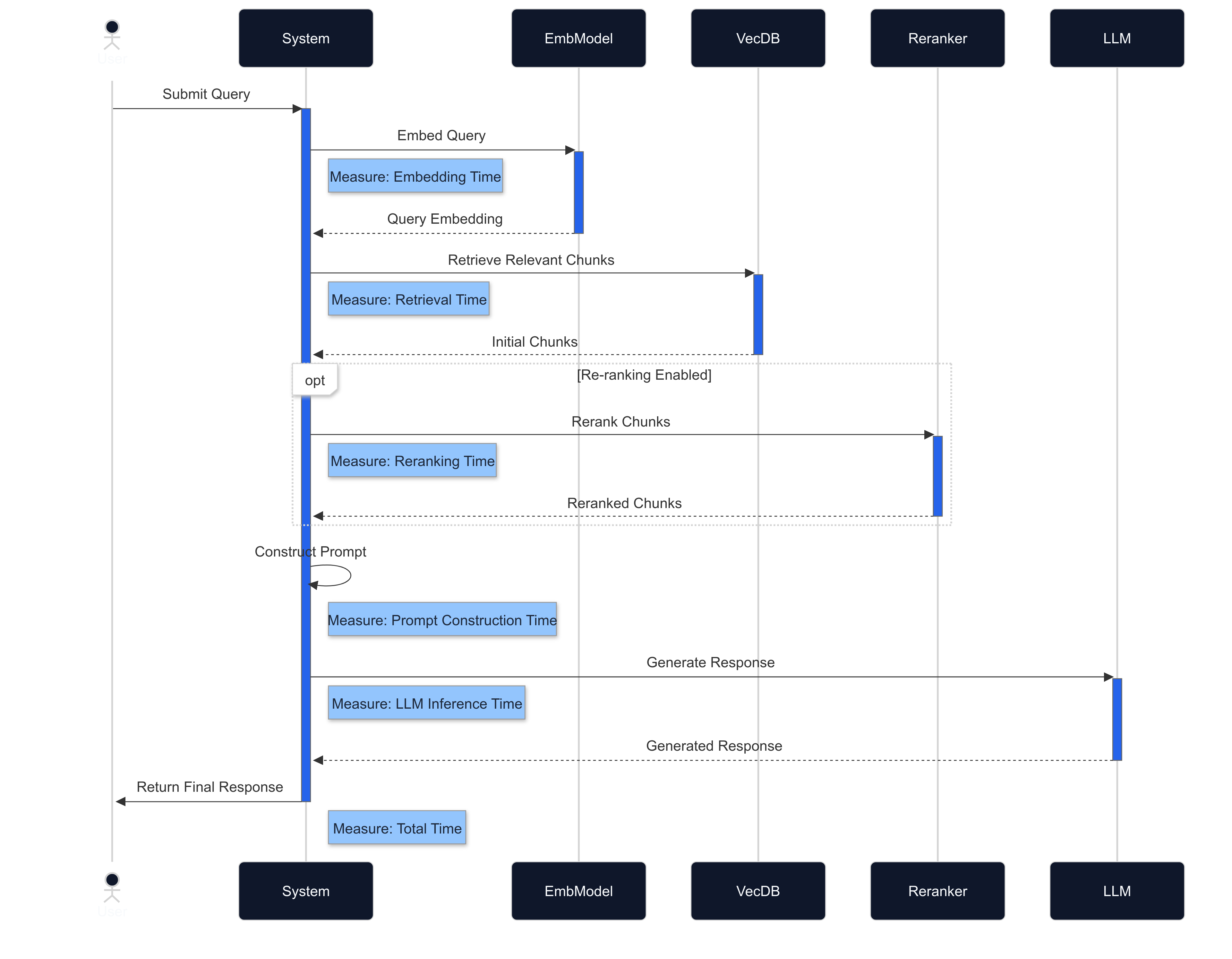
Fig 3: Visualizing the RAG query lifecycle and component interactions, highlighting key stages for performance monitoring and optimization.
Performance Bottleneck Analysis
Implement comprehensive logging and profiling to identify bottlenecks:
1def process_query(query, **kwargs):
2 """Process a query with timing instrumentation."""
3 metrics = {
4 "total_time_ms": 0,
5 "embedding_time_ms": 0,
6 "retrieval_time_ms": 0,
7 "reranking_time_ms": 0,
8 "prompt_construction_time_ms": 0,
9 "llm_inference_time_ms": 0,
10 }
11
12 start_time = time.time()
13
14 # Embedding step
15 embedding_start = time.time()
16 query_embedding = embed_query(query)
17 metrics["embedding_time_ms"] = (time.time() - embedding_start) * 1000
18
19 # Retrieval step
20 retrieval_start = time.time()
21 results = vector_store.retrieve(query_embedding, **kwargs)
22 metrics["retrieval_time_ms"] = (time.time() - retrieval_start) * 1000
23
24 # Reranking step
25 reranking_start = time.time()
26 reranked_results = reranker.rerank(query, results)
27 metrics["reranking_time_ms"] = (time.time() - reranking_start) * 1000
28
29 # Prompt construction
30 prompt_start = time.time()
31 prompt = construct_prompt(query, reranked_results)
32 metrics["prompt_construction_time_ms"] = (time.time() - prompt_start) * 1000
33
34 # LLM inference
35 llm_start = time.time()
36 response = llm.generate(prompt)
37 metrics["llm_inference_time_ms"] = (time.time() - llm_start) * 1000
38
39 # Total time
40 metrics["total_time_ms"] = (time.time() - start_time) * 1000
41
42 # Log metrics for analysis
43 logger.info(f"Query processing metrics: {metrics}")
44
45 return response, metrics
46Analyze this data to identify your primary bottlenecks:
- If embedding generation is the bottleneck: Consider smaller/faster embedding models, batch processing, or caching frequent queries.
- If vector search is the bottleneck: Optimize index parameters, consider approximate vs. exact search trade-offs, or upgrade your vector store infrastructure.
- If LLM inference is the bottleneck: Explore model quantization, smaller models, response streaming, or inference optimization frameworks like vLLM.
Monitoring and Evaluation Metrics
Establish comprehensive monitoring across these dimensions:
System Health Metrics:
- End-to-end latency (mean, p95, p99)
- Queries per second (QPS)
- Error rates
- Resource utilization (CPU, memory, GPU)
Retrieval Quality Metrics:
- Mean Reciprocal Rank (MRR)
- Precision@K
- Query coverage (% of queries with relevant results)
Generation Quality Metrics:
- Factual accuracy (human-evaluated or automated)
- Relevance to query
- Citation accuracy
- Hallucination rate
Leadership Perspective: Like any system, successful RAG implementations often benefit from comprehensive instrumentation and explicit metrics established early in development. This allows teams to make data-driven decisions throughout the process rather than relying on anecdotal evidence.
Implementation Strategies by Organization Size
Leadership Takeaway: The ideal RAG architecture depends significantly on your organization's size, existing infrastructure, and team capabilities.
Lean teams, pre-product market fit/Series A
Leadership Takeaway: Start simple with managed services to demonstrate business value quickly. Focus on core functionality before optimization.
- Focus on Speed-to-Value: Start with managed services for vector databases and LLMs
- Simplify Architecture: Begin with core RAG components before adding complexity
- Leverage Frameworks: Use LangChain, LlamaIndex, or similar frameworks to accelerate development
- Security Considerations: Implement basic access controls and encryption using managed service providers' built-in capabilities
- DR Strategy: Begin with basic automated snapshots of vector databases
- Systematic Evaluation & Iteration: Define retrieval metrics; log key RAG data (queries, context details & scores, LLM outputs, feedback) for analysis and iterative improvement.
- Recommended Stack: OpenAI embeddings + VectorDB(Pinecone/Qdrant) + OpenAI Api/Claude/Gemini
Engineer To-Do: Implement basic RAG with managed services, establish evaluation metrics, and document core architectural decisions.
Scaling teams with product-market fit
Leadership Takeaway: Balance managed and custom components. Establish clear ownership boundaries between teams working on different RAG components.
- Hybrid Approach: Custom components for critical performance areas, managed services elsewhere
- Systematic Evaluation: Invest in rigorous testing and evaluation frameworks
- Component Selection: Prioritize customizing high-impact areas first
- Security Implementation: Add dedicated security layers around vector stores and implement metadata-based access controls
- DR Strategy: Implement cross-region replication and regular recovery testing
- Recommended Stack: Custom embedding models + managed vector database + hybrid LLM approach
Engineer To-Do: Build internal APIs between components, implement robust monitoring, and establish golden-set regression tests.
Regulated / high-throughput organizations
Leadership Takeaway: Focus on scalability, compliance, and integration with existing enterprise systems. Establish specialized teams for each component.
- Specialized RAG Pipelines: Build optimized pipelines for specific business domains
- Robust Infrastructure: Dedicated, scalable infrastructure with comprehensive monitoring
- Advanced Techniques: Implement sophisticated retrieval and context processing optimizations
- Enterprise Security: Implement advanced security patterns like homomorphic encryption, row-level security, and data lineage tracking
- DR Strategy: Multi-region active/passive or active/active deployments with automated failover
- Recommended Stack: Fine-tuned embedding models + scalable distributed vector store + custom LLM hosting
Engineer To-Do: Implement multi-region architecture, advanced security controls, and comprehensive evaluation frameworks across the entire RAG pipeline.
Advanced Evaluation Metrics for RAG Systems
Leadership Takeaway: Comprehensive evaluation is critical for measuring ROI and guiding optimization efforts. Invest in both retrieval and generation metrics.
Traditional evaluation metrics like precision and recall are insufficient for fully assessing RAG system quality. Modern RAG evaluation requires a comprehensive approach that measures both retrieval effectiveness and response generation quality using specialized metrics.
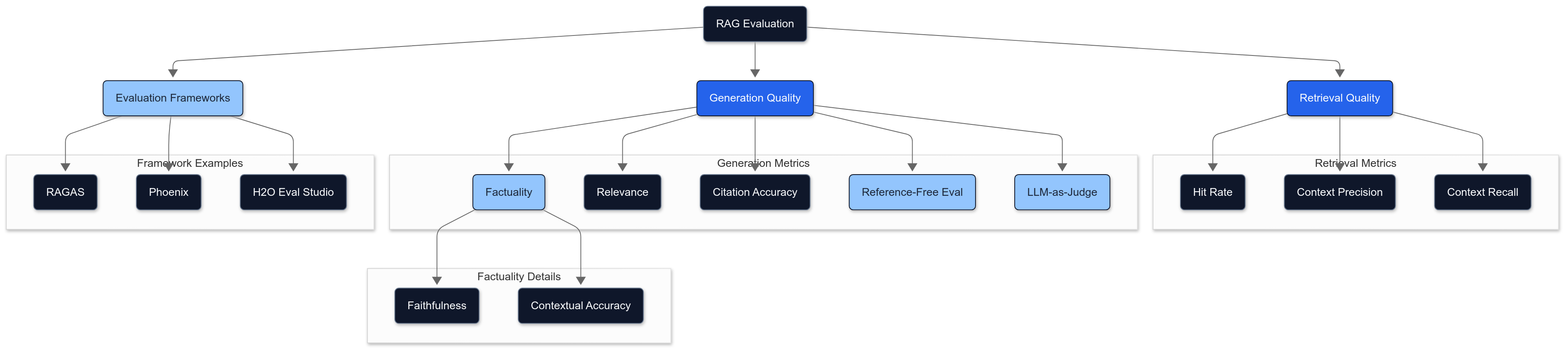
Core RAG Evaluation Dimensions
1. Retrieval Quality Metrics
Beyond traditional information retrieval metrics, RAG systems benefit from:
- Hit Rate: Percentage of queries where relevant context was successfully retrieved
- Context Precision: Evaluates whether retrieved documents contain only the information needed to answer the query, without extraneous content
- Context Recall: Measures how completely the retrieved documents cover the information needed
- Contextual Relevance to Query : Assesses how pertinent each retrieved document/chunk is to the user's query, ensuring the context provided to the LLM is on-topic and useful. This is often evaluated using an LLM to score the relevance of each retrieved item against the query.
If you have relevance-judged document lists (i.e., for a given query, you know which documents in your corpus are relevant), then standard IR metrics like Precision@k, Recall@k, Mean Average Precision (MAP), Mean Reciprocal Rank (MRR), and NDCG@k are valuable for assessing the core ranking quality of your retriever.
1def measure_context_recall(retrieved_docs, ground_truth_sentences, thresh=0.75):
2 """
3 Proportion of ground-truth sentences whose meaning appears
4 in at least one retrieved document.
5 """
6 # Pre-compute embeddings once for efficiency
7 doc_embs = [embed_model.embed_text(doc.text) for doc in retrieved_docs]
8
9 covered = 0
10 for sent in ground_truth_sentences:
11 sent_emb = embed_model.embed_text(sent)
12 if any(cosine_similarity(sent_emb, doc_emb) > thresh for doc_emb in doc_embs):
13 covered += 1
14
15 return covered / len(ground_truth_sentences) if ground_truth_sentences else 0.0
16
172. Generation Quality Metrics
Recent advances in LLM-specific evaluation have introduced powerful metrics for assessing RAG outputs:
Factuality Metrics
- Faithfulness: Measures if the generated answer is factually consistent with the retrieved context. This focuses on ensuring the answer avoids hallucinations (information not present in the context) and does not contradict the provided documents.
- Contextual Accuracy: Assesses if the information from the retrieved context that *is* used in the answer is represented accurately and without distortion or misinterpretation of the source documents.
1# Example implementation of faithfulness measurement (simplified concept)
2def evaluate_faithfulness(query, response, context_docs):
3 """Evaluate if all claims in the response are supported by the context."""
4 # Extract claims from the response
5 claims = claim_extractor.extract_claims(response) # Assumes a claim extraction mechanism
6
7 # Check each claim against the context
8 supported_claims = 0
9 for claim in claims:
10 if is_claim_supported(claim, context_docs): # Assumes a claim support checking mechanism
11 supported_claims += 1
12
13 # Calculate faithfulness score
14 faithfulness_score = supported_claims / len(claims) if claims else 1.0 # All claims supported if no claims
15
16 return faithfulness_score
17Engineer To-Do: Implement automated evaluation pipelines that track these metrics over time and alert on significant degradations.
Reference-Free Evaluation
Modern evaluation approaches have moved beyond requiring reference answers:
- GPTScore: Uses an LLM to evaluate the likelihood of the generated response given the input, offering a nuanced quality score (e.g., for fluency) without needing a reference answer.
- SelfCheckGPT: A sampling-based approach for fact-checking LLM outputs based on the premise that hallucinated content is not consistently reproducible across multiple generations.
LLM-as-Judge Evaluation
The LLM-as-Judge approach has become a standard for comprehensive evaluation:
1def llm_evaluation(query, response, context, criteria):
2 """Use an LLM to evaluate response quality based on specific criteria."""
3 prompt = f"""
4 You are an expert evaluator of RAG systems. Assess the following response:
5
6 Query: {query}
7
8 Retrieved Context: {context}
9
10 Response: {response}
11
12 Evaluate the response on a scale of 0-5 for the following criteria: {criteria}
13 Provide a brief explanation before giving your score.
14 """
15
16 evaluation = llm.generate(prompt)
17 return parse_evaluation_score(evaluation)
18Research shows that LLM-as-judge evaluations can achieve over 80% agreement with human evaluators on metrics like correctness and readability when using few-shot prompting with clear grading criteria.
Holistic RAG Evaluation Frameworks
Several frameworks have emerged to standardize RAG evaluation:
- RAGAS: A specialized framework for RAG evaluation that measures faithfulness, answer relevance, context relevance, and context recall without requiring annotated datasets
- Arize Phoenix: Offers comprehensive evaluation capabilities for LLM applications with specific RAG-oriented metrics
Implementing Effective Evaluation
For practical implementation, consider these recommendations:
- Use appropriate grading scales: While binary (0/1) scales seem simple and quick, we can use 3-5 point scales to capture nuanced RAG quality, guiding more effective iteration.
- Employ few-shot examples: Providing 1-2 examples per grade significantly improves evaluation consistency
- Combine automated and human evaluation: Start with automated metrics for efficiency, then validate key results with human reviewers
- Evaluate at component level: Assess retrieval and generation separately before end-to-end evaluation
By implementing these advanced evaluation techniques, engineering teams can iteratively improve RAG systems with confidence, focusing optimization efforts where they'll have the greatest impact.
Security & Governance: A Comprehensive Framework
To implement robust security and governance for RAG systems, a structured approach is essential. Let's break down the key components into manageable subcategories:

1. Access Control
Access control mechanisms determine who can access what data within your RAG system:
Row-Level Security (RLS)
Row-level security enables fine-grained access control at the data level. This ensures users only retrieve documents they have permission to view:
1-- Example of implementing RLS in PostgreSQL with pgvector
2ALTER TABLE document_sections ENABLE ROW LEVEL SECURITY;
3
4-- Create a policy that restricts access based on document ownership
5CREATE POLICY "Users can only access their own documents"
6ON document_sections
7USING (
8 document_id IN (
9 SELECT id FROM documents WHERE owner_id = current_user
10 )
11);
12Metadata-Based Filtering
When vector databases don't natively support RLS, metadata filtering provides an alternative approach:
1def secure_retrieval(query, user_id, user_permissions):
2 """Retrieve documents with security filtering."""
3 # First generate the query embedding
4 query_embedding = embedding_model.embed_query(query)
5
6 # Define security filters based on user permissions
7 security_filters = {
8 "accessible_to": {"$contains": user_id},
9 "classification": {"$in": user_permissions.clearance_levels},
10 "department": {"$in": user_permissions.departments}
11 }
12
13 # Perform secure retrieval with filters
14 results = vector_store.similarity_search(
15 query_embedding,
16 filter=security_filters,
17 k=5
18 )
19
20 return results
21Role-Based Access Control
Implement organizational roles that determine access patterns:
1# Define role-based permissions for RAG system
2ROLE_PERMISSIONS = {
3 "admin": {
4 "can_retrieve": ["public", "internal", "confidential", "restricted"],
5 "can_modify": ["public", "internal", "confidential", "restricted"],
6 "max_results": 100
7 },
8 "manager": {
9 "can_retrieve": ["public", "internal", "confidential"],
10 "can_modify": ["public", "internal"],
11 "max_results": 50
12 },
13 "employee": {
14 "can_retrieve": ["public", "internal"],
15 "can_modify": ["public"],
16 "max_results": 20
17 },
18 "guest": {
19 "can_retrieve": ["public"],
20 "can_modify": [],
21 "max_results": 10
22 }
23}
242. Encryption & Privacy
Protect sensitive data through comprehensive encryption strategies:
Encryption at Rest
All vector data should be encrypted in storage:
1# Example of configuring encryption for vector store
2def configure_encryption(vector_store, kms_key_id):
3 """Configure encryption for vector database."""
4 encryption_config = {
5 "algorithm": "AES-256-GCM",
6 "key_management": "aws_kms",
7 "kms_key_id": kms_key_id,
8 "auto_rotate": True,
9 "rotation_period_days": 90
10 }
11
12 return vector_store.set_encryption(encryption_config)
13Encryption in Transit
Ensure data is encrypted when moving between components:
1# Example configuration for secure communication between components
2def configure_secure_transport(client_config):
3 """Configure TLS for secure communication."""
4 security_config = {
5 "tls_enabled": True,
6 "verify_certificates": True,
7 "min_tls_version": "TLSv1.3",
8 "cipher_suite": "TLS_AES_256_GCM_SHA384",
9 "certificate_path": "/path/to/cert.pem",
10 "private_key_path": "/path/to/key.pem"
11 }
12
13 return client_config.update_security(security_config)
14Vector Inversion Protection
Protect against inversion attacks that attempt to reconstruct original data from embeddings:
1def apply_vector_privacy(embedding, privacy_level=0.1):
2 """Apply privacy-preserving noise to embeddings."""
3 # Add small random noise to prevent exact reconstruction
4 noise = np.random.normal(0, privacy_level, embedding.shape)
5 privatized_embedding = embedding + noise
6
7 # Renormalize if using cosine similarity
8 privatized_embedding = privatized_embedding / np.linalg.norm(privatized_embedding)
9
10 return privatized_embedding
11While homomorphic encryption represents a theoretically robust security approach for vector stores, note that it introduces significant computational overhead that makes it impractical for most real-time RAG workloads as of 2025. Consider this approach only for highly sensitive data where latency is not a primary concern.
3. Data Lifecycle & Audit
Implement comprehensive tracking of data through its lifecycle:
Data Catalog Integration
Maintain a record of all data sources flowing into your RAG system:
1def register_data_source(source_id, source_type, metadata):
2 """Register a data source in the data catalog."""
3 source_info = {
4 "id": source_id,
5 "type": source_type,
6 "ingestion_date": datetime.utcnow().isoformat(),
7 "owner": metadata.get("owner", "unknown"),
8 "classification": metadata.get("classification", "internal"),
9 "retention_policy": metadata.get("retention_policy", "standard"),
10 "metadata": metadata
11 }
12
13 data_catalog.register_source(source_info)
14 return source_info
15Lineage Tracking
Monitor how data flows through your RAG system:
1def track_data_lineage(query_id, user_id, query_text, retrieved_docs, generated_response):
2 """Track data lineage for audit and governance."""
3 lineage_record = {
4 "query_id": query_id,
5 "timestamp": datetime.utcnow().isoformat(),
6 "user_id": user_id,
7 "query_text": query_text,
8 "retrieved_document_ids": [doc.metadata["id"] for doc in retrieved_docs],
9 "response_id": generate_unique_id(),
10 "model_version": current_model_version,
11 "embedding_model_version": current_embedding_version
12 }
13
14 lineage_db.insert(lineage_record)
15 return lineage_record
16Retention Policies
Enforce data lifecycle management:
1def apply_retention_policy(vector_store):
2 """Apply data retention policies to vector database."""
3 # Find documents that have exceeded retention period
4 expired_docs = vector_store.find({
5 "ingestion_date": {"$lt": datetime.utcnow() - timedelta(days=365)},
6 "retention_policy": "standard"
7 })
8
9 # Process documents based on retention policy
10 for doc in expired_docs:
11 if doc.metadata.get("archive_required", False):
12 # Archive document before removal
13 archive_document(doc)
14 else:
15 # Permanently delete
16 vector_store.delete([doc.id])
17
18 return len(expired_docs)
19By implementing this comprehensive security and governance framework, organizations can ensure their RAG systems maintain appropriate data protection while still delivering value to authorized users.
Operations & Reliability: Disaster Recovery for Vector Databases
Leadership Takeaway: Robust disaster recovery strategies are essential for production RAG systems. Plan for component-level and system-level failures from the start.
Ensuring the reliability of your RAG system requires robust disaster recovery strategies, particularly for vector databases which store critical knowledge embeddings.
Multi-Region Replication
Implementing cross-region replication provides geographical redundancy that protects against regional outages:
1# Example of configuring cross-region replication for a vector store
2def configure_cross_region_replication(primary_vector_store, backup_region):
3 """Set up asynchronous cross-region replication for vector database."""
4 replication_config = {
5 "enabled": True,
6 "target_region": backup_region,
7 "replication_frequency": "continuous", # or "hourly", "daily"
8 "include_indexes": True,
9 "recovery_point_objective_minutes": 15
10 }
11
12 return primary_vector_store.enable_replication(replication_config)
13For production deployments, consider these disaster recovery patterns:
- Automated Snapshots: Schedule regular vector database snapshots with retention policies.
- Point-in-Time Recovery: Enable transaction logging to support rollback to specific moments.
- Restore Drills: Regularly test your disaster recovery process by performing actual restores in a staging environment.
1# Example of snapshot-based backup strategy
2def schedule_vector_db_snapshots(vector_store, bucket_name):
3 """Configure automated snapshots for vector database."""
4 snapshot_config = {
5 "schedule": "0 1 * * *", # Daily at 1 AM (cron syntax)
6 "retention_days": 30,
7 "storage_location": f"s3://{bucket_name}/backups/",
8 "encryption_enabled": True
9 }
10
11 return vector_store.create_backup_schedule(snapshot_config)
12Multi-region disaster recovery solutions typically replicate data at either the storage level or database level. AWS offers cross-region read replicas for managed database services, which can be used for both disaster recovery and read scaling across geographic regions.
Engineer To-Do: Implement automated snapshot backups with cross-region replication and document the restore process step-by-step.
Model Versioning & Rollback
As embedding models and LLMs evolve, maintaining version compatibility becomes crucial:
1# Example of tracking model versions in your deployment
2def register_model_version(model_type, model_name, version, metadata=None):
3 """Register a model version for tracking and potential rollback."""
4 metadata = metadata or {}
5 version_info = {
6 "model_type": model_type, # "embedding" or "llm"
7 "model_name": model_name,
8 "version": version,
9 "deployed_at": datetime.utcnow().isoformat(),
10 "vector_store_snapshot": f"snapshot_{datetime.utcnow().strftime('%Y%m%d')}",
11 "metadata": metadata
12 }
13
14 model_registry.add_version(version_info)
15 return version_info
16Implement regression testing with golden-set examples to validate new models before deployment:
1def validate_model_upgrade(old_model, new_model, test_queries):
2 """Validate new model against benchmark examples before switchover."""
3 results = {"passed": 0, "failed": 0, "degraded": 0, "details": []}
4
5 for query in test_queries:
6 old_result = old_model.generate(query)
7 new_result = new_model.generate(query)
8
9 # Compare results using appropriate metrics
10 similarity = semantic_similarity(old_result, new_result)
11 factuality = evaluate_factuality(new_result, query)
12
13 # Track results
14 if factuality < 0.8:
15 results["failed"] += 1
16 status = "FAILED"
17 elif similarity < 0.7:
18 results["degraded"] += 1
19 status = "DEGRADED"
20 else:
21 results["passed"] += 1
22 status = "PASSED"
23
24 results["details"].append({
25 "query": query,
26 "status": status,
27 "similarity": similarity,
28 "factuality": factuality
29 })
30
31 return results["failed"] == 0, results
32When implementing both database replication and model versioning, carefully track the relationships between embedding model versions and their corresponding vector databases to ensure compatibility during recovery operations.
Advanced & Emerging Techniques
Leadership Takeaway: Stay informed about emerging techniques to make strategic decisions about when to adopt new approaches that can provide competitive advantage. Be aware of technology maturity levels when planning implementation timelines.
As RAG technologies continue to evolve, several emerging approaches are worth monitoring for potential integration into your implementation strategy. Note that many of these techniques remain research-grade and may require further maturation before enterprise-ready implementation.
RAFT: Retrieval-Augmented Fine-Tuning
Retrieval-Augmented Fine-Tuning (RAFT) represents an innovative evolution beyond traditional RAG by combining retrieval capabilities with model fine-tuning. This approach effectively bridges the gap between RAG and standard fine-tuning methods. While promising, RAFT is still primarily research-grade with limited production implementations as of 2025.
1# Simplified RAFT training example
2def prepare_raft_training_data(question, context_docs, distractor_docs):
3 """Prepare training data for RAFT with distractor handling."""
4 # Select a mix of relevant and distractor documents
5 combined_docs = context_docs[:2] + distractor_docs[:3]
6 random.shuffle(combined_docs)
7
8 # Format the training example
9 training_example = {
10 "question": question,
11 "documents": combined_docs,
12 "answer": generate_cot_answer(question, context_docs), # Chain-of-thought answer
13 "has_answer": len(context_docs) > 0
14 }
15
16 return training_example
17RAFT offers several advantages over traditional approaches:
- Distractor Document Handling: RAFT trains models to ignore irrelevant documents, making retrieval more robust.
- Chain-of-Thought Responses: Models are trained to produce reasoning-based answers with proper citations.
- Domain Specialization: Models can be efficiently adapted to specialized domains without losing their general capabilities.
Early benchmarks show that RAFT-trained models often outperform both vanilla fine-tuning and standard RAG approaches, especially for domain-specific applications where the knowledge domain is well-defined.
Engineer To-Do: Experiment with RAFT on smaller domain-specific datasets before considering wider deployment. Compare performance against standard RAG using your evaluation metrics.
Other Emerging Techniques
Several other techniques are gaining traction in advanced RAG implementations:
- Multimodal RAG: Extending retrieval beyond text to include images, audio, and video as contextual information sources.
- Agentic RAG: Implementing RAG within autonomous agent frameworks that can make decisions about when and what to retrieve.
- Self-improving RAG: Systems that automatically refine their retrieval and generation components based on user feedback and performance metrics.
Staying informed about these emerging trends will help engineering leaders make strategic decisions about when and how to incorporate these advancements into their RAG implementations.
Implementation Aids
Leadership Takeaway: Leveraging established open-source tools and frameworks can significantly reduce time-to-value for your RAG implementation.
To help you move from concept to implementation more quickly, here are some practical resources and starter templates to accelerate your RAG journey.
GitHub Repositories
Several high-quality repositories provide excellent starting points for RAG implementation:
- LlamaIndex Starter Templates: Comprehensive examples covering various use cases and integrations.
- LangChain RAG Template: A conversational RAG implementation that can be adapted to specific needs.
- Haystack RAG Pipeline: Production-ready RAG pipeline examples with various retrieval approaches.
- Chroma RAG Template: Simple and effective RAG implementation using Chroma vector database.
Engineer To-Do: Fork one of these repositories as a starting point and adapt it to your specific use case and requirements.
Operational "Gotchas" to Avoid
Leadership Takeaway: Anticipating common operational pitfalls can save significant time and resources down the line. Build these considerations into your planning process.
Throughout our consulting engagements, we've identified several common operational challenges that can derail even well-designed RAG implementations. Being aware of these issues can help you avoid costly mistakes.
Hot-Reload Failures
When embedding schema changes occur (such as switching from 1536d to 3072d embeddings), hot-reloads may fail, requiring full reindexing:
1# Monitor for embedding dimension changes
2def check_embedding_compatibility(existing_dim, new_embedding):
3 """Check if new embeddings are compatible with existing index."""
4 new_dim = len(new_embedding)
5 if existing_dim != new_dim:
6 logger.warning(
7 f"Embedding dimension mismatch: index={existing_dim}, new={new_dim}. "
8 f"Full reindexing required!"
9 )
10 return False
11 return True
12Mitigation: Design your system to detect dimension changes and trigger controlled reindexing processes during off-peak hours.
Index Drift
Staging and production environments can drift over time, leading to performance discrepancies:
1# Compare index statistics between environments
2def compare_index_stats(prod_stats, staging_stats, threshold=0.1):
3 """Compare index statistics between environments."""
4 drift_metrics = {}
5
6 # Check vector count drift
7 vector_count_diff = abs(prod_stats["vector_count"] - staging_stats["vector_count"]) / prod_stats["vector_count"]
8 drift_metrics["vector_count_drift"] = vector_count_diff
9
10 # Check index parameters drift
11 for param in ["ef_construction", "m"]:
12 if prod_stats["index_params"][param] != staging_stats["index_params"][param]:
13 drift_metrics[f"{param}_drift"] = True
14
15 # Check overall drift
16 drift_detected = any(
17 isinstance(v, bool) and v or
18 isinstance(v, (int, float)) and v > threshold
19 for v in drift_metrics.values()
20 )
21
22 return drift_detected, drift_metrics
23Mitigation: Implement regular index comparison checks and automated synchronization processes.
Cold-Start Latency Spikes
Vector databases often experience significant latency spikes after scaling down or cold starts:
1# Implement a warm-up process
2def warmup_vector_store(vector_store, common_queries):
3 """Warm up vector store to minimize cold-start latency."""
4 results = []
5 for query in common_queries:
6 # Execute a series of typical queries to warm caches
7 query_embedding = embedding_model.embed_query(query)
8 results.append(vector_store.search(query_embedding, top_k=10))
9
10 logger.info(f"Vector store warmed up with {len(common_queries)} queries")
11 return results
12Mitigation: Implement warm-up procedures and consider keeping a minimum level of resources allocated even during low-traffic periods.
Engineer To-Do: Implement monitoring for these common issues, with alerts when concerning patterns are detected. Document recovery procedures for each scenario.
Cost & Budgeting: Understanding RAG Total Cost of Ownership
Leadership Takeaway: Understanding the full cost structure of your RAG implementation is essential for sustainable scaling and budgeting.
When planning a RAG implementation, it's essential to consider the total cost of ownership (TCO) across different components. Below is a high-level comparison of costs for key RAG components:
| Component | Cost Level | Major Cost Drivers | Cost Optimization Strategies |
|---|---|---|---|
| **Embedding Generation** | $ - $$ | API costs for commercial models<br>Compute for self-hosted models<br>Volume of data processed | Batch processing<br>Caching frequent queries<br>Open-source models |
| **Vector Database** | $ - $$ | Storage volume<br>Query volume<br>Managed vs. self-hosted | Optimized index parameters<br>Pruning outdated data<br>Tiered storage strategies |
| **LLM Inference** | $ - $$ | Model size and complexity<br>Response length<br>Query volume | Model quantization<br>Context pruning<br>Response caching<br>Hybrid model approach |
| **Infrastructure** | $ - $$ | High-availability requirements<br>Geographic distribution<br>Backup and redundancy | Right-sizing resources<br>Serverless computing<br>Spot instances for batch processing |
| **Data Processing** | $ - $$ | Data volume<br>Preprocessing complexity<br>Update frequency | Incremental updates<br>Asynchronous processing<br>Optimized chunking strategies |
| **Operations** | $ | Monitoring and observability<br>Maintenance and updates<br>Security and compliance | Automation<br>DevOps integration<br>Standardized deployment patterns |
Cost levels: $ = Low, $ = Medium, $$ = High, $$ = Very High
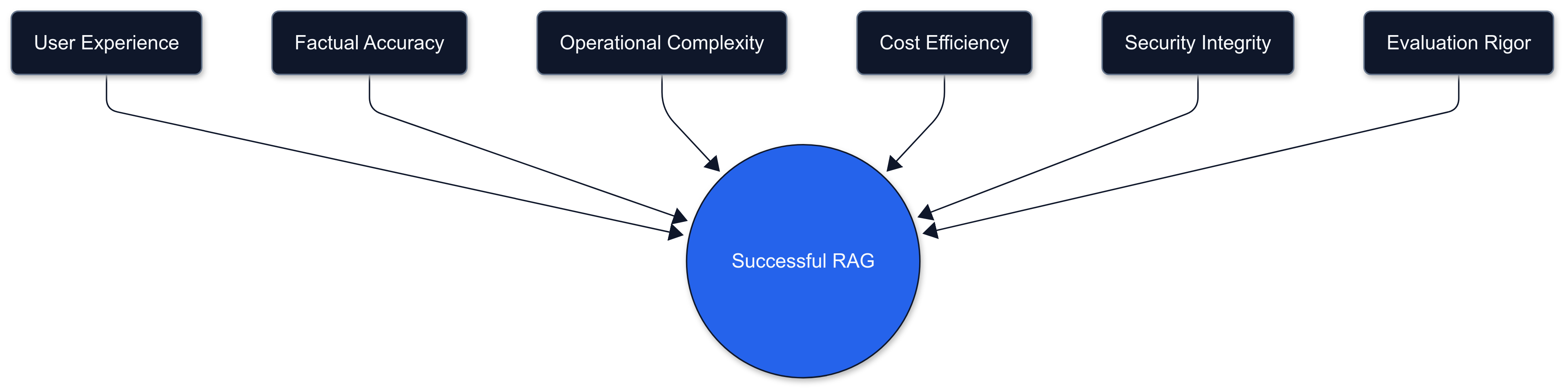
Conclusion: Balancing the Six Critical Dimensions
As you implement your RAG system, remember that successful deployment requires balancing six key considerations:
- User experience: Particularly latency and relevance
- Factual accuracy: The core value proposition of RAG
- Operational complexity: How much engineering effort is required for maintenance
- Cost efficiency: Both in terms of infrastructure and API costs
- Security integrity: Protecting sensitive data and ensuring appropriate access
- Evaluation rigor: Implementing comprehensive metrics to measure system quality
By following the framework outlined in this guide, you can navigate these trade-offs systematically, resulting in RAG systems that deliver real business value through improved accuracy, trust, and capabilities, all while maintaining robust security posture.
References and Further Reading
- Supabase. (2024). "RAG with Permissions." Supabase Documentation. https://supabase.com/docs/guides/ai/rag-with-permissions
- Cloud Security Alliance. (2023). "Mitigating Security Risks in RAG LLM Applications." CSA Blog. https://cloudsecurityalliance.org/blog/2023/11/22/mitigating-security-risks-in-retrieval-augmented-generation-rag-llm-applications
- Zilliz. (2024). "How to Ensure Data Security in RAG Systems." Zilliz Blog. https://zilliz.com/blog/ensure-secure-and-permission-aware-rag-deployments
- Privacera. (2024). "Privacera Enhances AI Governance Solution with New Access Control and Data Filtering Functionality for Vector DB/RAG." https://privacera.com/newsroom/press-releases/privacera-enhances-ai-governance-solution-with-new-access-control-and-data-filtering-functionality-for-vector-db-rag/
- AWS. (2024). "Providing secure access, usage, and implementation to generative AI RAG techniques." AWS Prescriptive Guidance. https://docs.aws.amazon.com/prescriptive-guidance/latest/security-reference-architecture/gen-ai-rag.html
- BigID. (2024). "Secure RAG Applications: Enhancing Security & Responsible AI with BigID and Elasticsearch Vector Database." BigID Blog. https://bigid.com/blog/secure-rag-applications-bigid-and-elasticsearch/
- Ragas. (2023). "Evaluation framework for RAG systems." https://github.com/explodinggradients/ragas
- Databricks. (2024). "Best Practices for LLM Evaluation of RAG Applications." Databricks Blog. https://www.databricks.com/blog/LLM-auto-eval-best-practices-RAG
- H2O. (2024). "Evaluators for RAG systems." H2O Eval Studio Documentation. https://docs.h2o.ai/eval-studio-docs/evaluators
- Arize AI. (2024). "Evaluate RAG with LLM Evals and Benchmarks." Arize AI Blog. https://arize.com/blog/evaluate-rag-with-llm-evals-and-benchmarking/
- Microsoft. (2024). "Evaluation metrics for LLM content." Microsoft Learn. https://learn.microsoft.com/en-us/ai/playbook/technology-guidance/generative-ai/working-with-llms/evaluation/list-of-eval-metrics
- Protecto AI. (2025). "Understanding LLM Evaluation Metrics For Better RAG Performance." Protecto AI Blog. https://www.protecto.ai/blog/understanding-llm-evaluation-metrics-for-better-rag-performance
- Confident AI. (2024). "LLM Evaluation Metrics: The Ultimate LLM Evaluation Guide." https://www.confident-ai.com/blog/llm-evaluation-metrics-everything-you-need-for-llm-evaluation
- Deepchecks. (2025). "LLM Evaluation Metrics: Ensuring Optimal Performance & Relevance." https://www.deepchecks.com/llm-evaluation-metrics/
- Evidently AI. (2024). "LLM evaluation metrics and methods." https://www.evidentlyai.com/llm-guide/llm-evaluation-metrics
- IronCore Labs. (2024). "Security Risks with RAG Architectures." https://ironcorelabs.com/security-risks-rag/
- Mend. (2024). "All About RAG: What It Is and How to Keep It Secure." https://www.mend.io/blog/all-about-rag-what-it-is-and-how-to-keep-it-secure/
- Zhang, J., et al. (2024). "RAFT: Adapting Language Model to Domain Specific RAG." https://arxiv.org/abs/2403.10131
- Red Hat Developer. (2024). "vLLM Inferencing for AI Applications." https://developers.redhat.com/articles/2025/04/05/llama-4-herd-here-day-zero-inference-support-vllm
- AWS. (2023). "Implementing a disaster recovery strategy with Amazon RDS." AWS Database Blog. https://aws.amazon.com/blogs/database/implementing-a-disaster-recovery-strategy-with-amazon-rds/
For code examples and implementation details, recommend consulting the documentation of the specific tools and frameworks mentioned throughout this article, including LangChain, LlamaIndex, various vector databases, and embedding model providers.