
Introduction: Why Chunking Matters in RAG Systems
Retrieval Augmented Generation (RAG) has become the cornerstone architecture for modern AI applications requiring knowledge-intensive responses. While much attention is paid to embedding models and LLM selection, one critical component often flies under the radar: the chunking strategy. This fundamental preprocessing step can dramatically impact your system's retrieval accuracy, context preservation, and operational performance.
As engineering leaders implementing AI solutions, understanding these tradeoffs is essential for designing systems that meet both technical requirements and business objectives.
Note: All code examples and data visualizations in this post are from our RAG Chunking Strategies experiment. The complete code, dataset, and analysis are available in our GitHub repository (MIT License).
The Business Value of Optimized Chunking
Before diving into technical details, let's address why chunking optimization matters from a business perspective:
- Improved accuracy: Better chunking leads to more relevant retrievals, resulting in higher-quality AI responses
- Reduced costs: Optimal chunk sizes minimize token usage and computational overhead
- Enhanced user experience: Preserving semantic coherence in chunks ensures contextually appropriate responses
- System scalability: The right chunking strategy can reduce processing time and infrastructure requirements as document volume grows
In our analysis, we observed that chunking strategy selection could produce a difference in retrieval quality while also significantly impacting processing speed and resource utilization.
Common Chunking Strategy Pitfalls
Organizations implementing RAG systems often fall into these traps:
- One-size-fits-all thinking: Using the same chunking approach for all content types
- Default configuration acceptance: Not tuning chunk sizes and overlaps for specific use cases
- Over-indexing on character count: Focusing on raw length while ignoring semantic coherence
- Ignoring retrieval evaluation: Implementing sophisticated strategies without measuring their actual retrieval performance
- Neglecting processing overhead: Not considering the computational cost of complex chunking strategies
Comparative Analysis: Chunking Strategies Explained
Let's examine the major chunking strategies and their performance characteristics:
Fixed-Size Character Chunking
1def chunk_fixed_size(text: str, chunk_size: int, chunk_overlap: int) -> list[str]:
2 """Chunks text into fixed-size character chunks."""
3 text_splitter = CharacterTextSplitter(
4 separator="\n\n", # Less important here as it mainly cuts by length
5 chunk_size=chunk_size,
6 chunk_overlap=chunk_overlap,
7 length_function=len,
8 is_separator_regex=False,
9 )
10 docs = text_splitter.create_documents([text])
11 return [doc.page_content for doc in docs]
12Characteristics:
- Simple implementation and minimal processing overhead
- Produces consistent-sized chunks, better for token prediction
- Ignores content structure, often breaking mid-sentence or paragraph
In our analysis using Kubernetes documentation as test content (with target chunk size of 1000 characters), fixed-size chunking produced the fewest chunks (only 3) but with very high variance in size. The mean length was 13,510 characters—far above our target size. This occurred because the algorithm found few natural breakpoints at "\n\n" separators in our content, causing it to create large chunks despite the target size parameter. This illustrates how content format significantly impacts fixed-size chunking's effectiveness.
Recursive Chunking
1def chunk_recursive(text: str, chunk_size: int, chunk_overlap: int) -> list[str]:
2 """Chunks text recursively using multiple separators, including Markdown headers."""
3 # Prioritize splitting larger structures first
4 markdown_separators = [
5 "\n## ", "\n### ", "\n#### ", # Headers
6 "\n\n", # Paragraphs
7 "\n", # Lines
8 ". ", "!", "?", # Sentences
9 ", ", "; ", # Clauses/Phrases
10 " ", # Words
11 "" # Characters
12 ]
13 separators = ["\n```\n", "\n---", "\n***"] + markdown_separators
14
15 text_splitter = RecursiveCharacterTextSplitter(
16 chunk_size=chunk_size,
17 chunk_overlap=chunk_overlap,
18 length_function=len,
19 is_separator_regex=False,
20 separators=separators,
21 )
22 docs = text_splitter.create_documents([text])
23 return [doc.page_content for doc in docs]
24Characteristics:
- More structure-aware than fixed-size chunking
- Attempts to split on logical boundaries (paragraphs, sentences)
- Slightly higher processing overhead
- Better preservation of context within chunks
Our analysis of the Kubernetes documentation showed recursive chunking created much more balanced distributions (47 chunks) with lengths closer to target size (mean: 924 chars). This improvement over fixed-size chunking occurred because the algorithm tried multiple separator types (headers, paragraphs, sentences) rather than relying on a single separator. The result was chunks that better respected both the target size and the document's natural structure.
Token-Based Recursive Chunking
1def chunk_tokens_recursive(text: str, tokenizer_name: str, chunk_size: int, chunk_overlap: int):
2 """Chunks text recursively based on token count."""
3 tokenizer = tiktoken.get_encoding(tokenizer_name)
4
5 def token_length(text: str) -> int:
6 return len(tokenizer.encode(text))
7
8 # Use same separators as the enhanced recursive chunker
9 text_splitter = RecursiveCharacterTextSplitter(
10 chunk_size=chunk_size,
11 chunk_overlap=chunk_overlap,
12 length_function=token_length, # Use token length function
13 separators=separators,
14 )
15 docs = text_splitter.create_documents([text])
16 return [doc.page_content for doc in docs]
17Characteristics:
- Token-aware instead of character-aware, better for LLM consumption
- More accurate length control aligned with model token windows
- Higher computational cost (tokenization overhead)
- Better prediction of actual costs in token-based pricing models
In our Kubernetes documentation test, this approach produced 36 chunks with a mean length of 1225 characters, and took slightly longer to process (0.05s vs 0.01s for recursive). The higher character count despite similar token targets reflects how tokenization works—certain content types (like code or structured text) tokenize differently than natural language. This difference illustrates why token-based approaches can provide better control over final LLM input sizes compared to character-based methods.
Natural Language Chunking (NLTK and spaCy)
1def chunk_sentences_nltk(text: str, target_chunk_size: int) -> list[str]:
2 """Chunks text by sentences (NLTK) and groups them."""
3 sentences = sent_tokenize(text)
4 chunks = []
5 current_chunk = ""
6 for sentence in sentences:
7 if not current_chunk or len(current_chunk) + len(sentence) + 1 <= target_chunk_size:
8 current_chunk += (" " + sentence).strip()
9 else:
10 chunks.append(current_chunk)
11 current_chunk = sentence
12 if current_chunk:
13 chunks.append(current_chunk)
14 return chunks
15Characteristics:
- Better linguistic awareness of sentence boundaries
- More natural chunk boundaries for human readability
- Moderate processing overhead
- May produce inconsistent chunk sizes depending on content
When applied to our Kubernetes documentation, NLTK sentence chunking produced 19 chunks with relatively large mean sizes (2125 chars), while spaCy produced 37 chunks with more consistent sizes. The difference between the two libraries stems from how they identify sentence boundaries—NLTK uses simpler rule-based detection, while spaCy employs more sophisticated linguistic models. In technical documentation with many code snippets and non-standard sentence structures, these differences became more pronounced.
Semantic Chunking (LangChain and LlamaIndex)
1def chunk_semantic_langchain(text: str, embedding_model_name: str, threshold_type: str, threshold_amount: float):
2 """Chunks text semantically using LangChain's SemanticChunker."""
3 embeddings = HuggingFaceEmbeddings(model_name=embedding_model_name)
4 text_splitter = SemanticChunker(
5 embeddings=embeddings,
6 breakpoint_threshold_type=threshold_type,
7 breakpoint_threshold_amount=threshold_amount
8 )
9 docs = text_splitter.create_documents([text])
10 return [doc.page_content for doc in docs]
11Characteristics:
- Content-aware splitting based on semantic meaning
- Higher computational overhead (requires embedding calculations)
- More sophisticated preservation of conceptual units
- Usually produces the best retrieval results
The LangChain semantic approach created the most chunks (157) but with the smallest mean size (257 chars), while LlamaIndex created only 9 larger chunks (mean: 4503 chars). In our experiment with Kubernetes documentation, this dramatic difference stemmed from how each library approaches semantic chunking. LangChain made more aggressive splits based on our threshold settings, creating numerous small but semantically coherent chunks. LlamaIndex, with its different chunking algorithm and threshold approach, created fewer but larger semantic units. Neither approach is inherently superior—the optimal choice depends on your specific retrieval requirements and content characteristics.
Parameter sensitivity note: Semantic chunking is highly dependent on parameter selection. In our experiment, LangChain semantic chunking used a `threshold_type` of "cosine_distance" with a `threshold_amount` of 0.5, while LlamaIndex used a `breakpoint_percentile_threshold` of 95. These different parameterizations explain the dramatic difference in output - LangChain created many smaller chunks, while LlamaIndex created fewer large chunks.
When implementing semantic chunking, you should expect to spend significant time tuning these parameters for your specific content. Key parameters to consider include:
- Embedding model selection: Different embedding models (e.g., all-MiniLM-L6-v2 vs. larger models) will produce different semantic boundaries
- Distance metrics: Cosine similarity vs. other distance calculations can yield very different results
- Threshold settings: Lower thresholds create more breakpoints (smaller chunks), while higher thresholds yield fewer breakpoints (larger chunks)
- Buffer sizes: How much text to consider when calculating semantic transitions
Evaluating Chunking Strategy Performance
Our experiment measured two key performance dimensions:
- Structural metrics:
- Chunk count and size distribution
- Processing time
- Adherence to target chunk size
- Retrieval metrics:
- Hit Rate: proportion of queries where the ground truth was retrieved in the top K results
- Mean Reciprocal Rank (MRR): average of the reciprocal ranks of first relevant retrievals
| Strategy | Chunk Count | Mean Length | Processing Time (s) | Hit Rate | MRR |
|---|---|---|---|---|---|
| Fixed-Size | 3 | 13510 | 0.00 | 0.00 | 0.00 |
| Recursive | 47 | 924 | 0.01 | 0.00 | 0.00 |
| Token Recursive | 36 | 1225 | 0.05 | 0.00 | 0.00 |
| NLTK Sentence | 19 | 2125 | 0.00 | 0.25 | 0.25 |
| spaCy Sentence | 37 | 1090 | 1.76 | 0.00 | 0.00 |
| Semantic (LangChain) | 157 | 257 | 9.78 | 1.00 | 1.00 |
| Semantic (LlamaIndex) | 9 | 4504 | 9.00 | 0.50 | 0.33 |
| Markdown Header | 2 | 20247 | 0.00 | 0.00 | 0.00 |
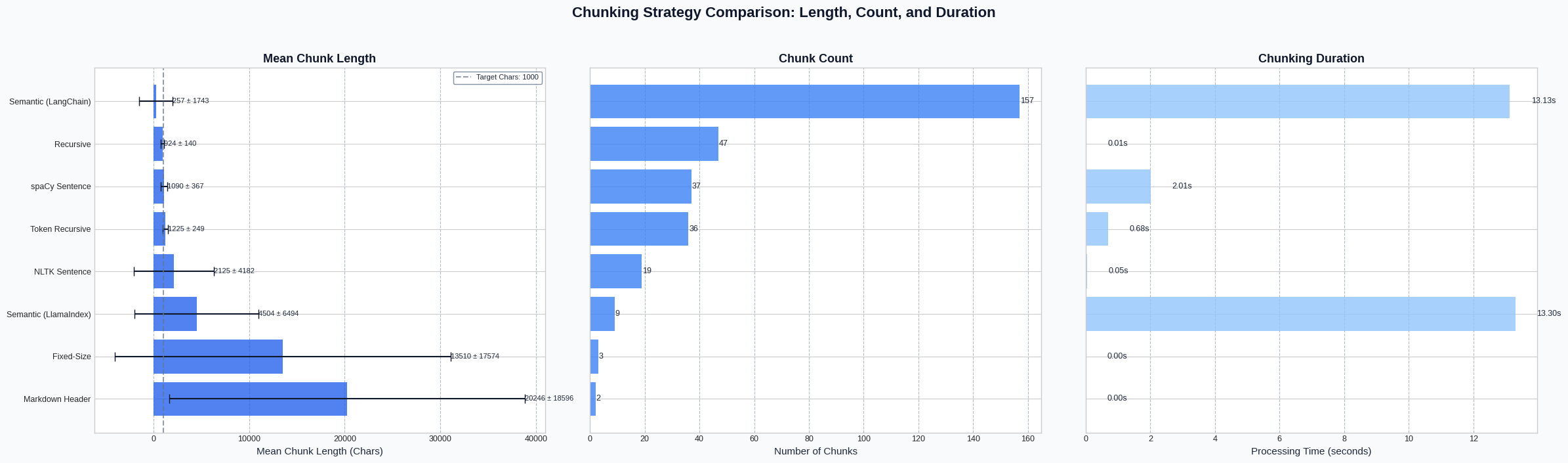
Figure 1: Side-by-side comparison of mean chunk length, chunk count, and processing duration. Note the significant processing time required for semantic approaches versus the minimal overhead of simpler strategies.
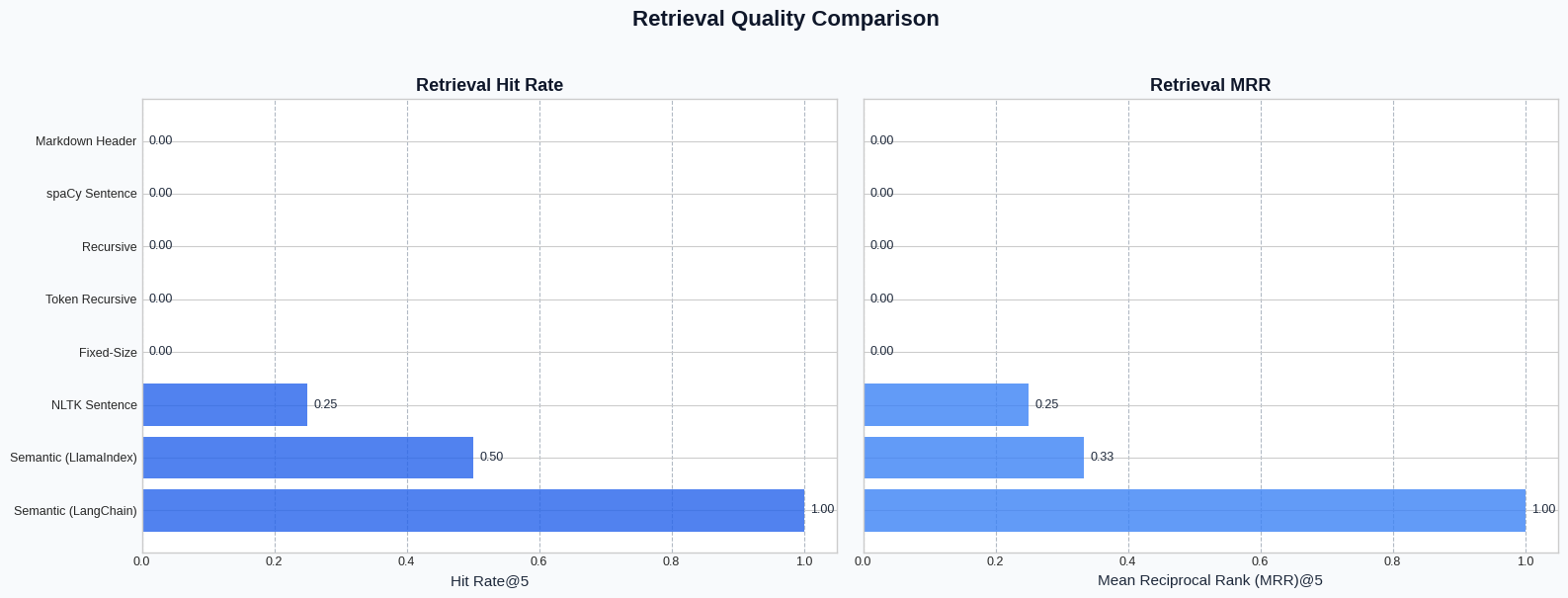
Figure 2: Retrieval quality metrics (Hit Rate and MRR) across strategies. Note that these results are specific to our test setup using LangChain semantic chunking as the baseline for ground truth. While semantic approaches show an advantage, the extreme differences would likely moderate in diverse real-world scenarios._
Key Insights for Engineering Leaders
Based on our analysis, here are actionable insights for implementing chunking strategies:
- Semantic chunking delivers superior retrieval performance but comes with significantly higher computational overhead. Consider using it for mission-critical applications where accuracy justifies the cost.
- Linguistic-aware methods (NLTK/spaCy) offer a good middle ground between simple character chunking and full semantic approaches, with reasonable retrieval performance and moderate processing requirements.
- Processing time matters at scale. For large document collections, the 9+ seconds required for semantic chunking can become a bottleneck. Consider pre-processing documents or implementing parallel chunking pipelines.
- Content structure should inform chunking strategy. Documents with clear section headers might benefit from Markdown header chunking, while narrative text may require semantic or linguistic approaches.
- Chunk size distribution impacts vector database performance. Extremely variable chunk sizes (as seen with fixed-size chunking) can negatively affect retrieval systems optimized for consistent input sizes.
Visualizing Chunk Size Variation
When implementing a RAG system, understanding how your chunking strategy affects chunk size distribution is critical. The violin plot below provides an illuminating view of this variation:
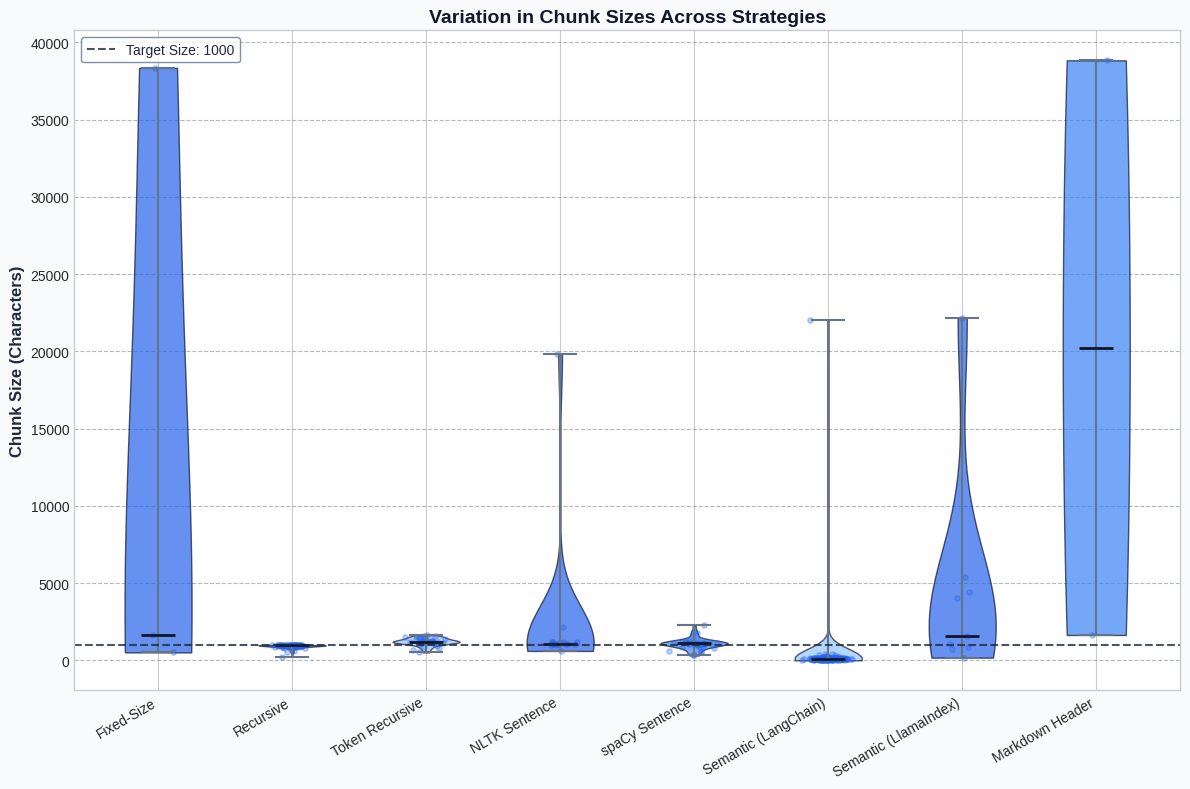
Figure 3: Violin plot showing the variation in chunk sizes across strategies. The width at each point indicates the density of chunks at that size. Note how semantic approaches (particularly LangChain) create more consistently sized chunks compared to the extreme variance in Fixed-Size and Markdown Header approaches.
This visualization reveals several important patterns:
- Fixed-Size and Markdown Header chunking produce extreme outliers, with some chunks being orders of magnitude larger than the target size.
- Recursive and Token-based chunking create more consistent distributions centered closer to the target chunk size.
- Semantic chunking with LangChain produces the most consistent distribution, with a high concentration of chunks near its target size.
- NLTK and spaCy approaches show moderate variance, with distributions that respect linguistic boundaries.
These patterns have direct implications for retrieval performance. More consistent chunk sizes tend to produce more reliable embedding vectors, while extreme outliers can distort semantic spaces and lead to retrieval failures.
Implementation Considerations for Different Organization Sizes
For Startups and Small Teams
- Balance of simplicity and effectiveness
- Focus on content-specific optimizations rather than computational efficiency at small scale
For Medium-Sized Organizations
- Consider hybrid approaches: semantic chunking for high-value content, simpler methods for the rest
- Implement a chunking evaluation framework to continuously measure retrieval performance
For Enterprise Organizations
- Design content-specific chunking pipelines based on document types and structures
- Build comprehensive evaluation systems that consider both retrieval quality and computational costs
- Consider implementing custom chunking logic for proprietary document formats or domain-specific content
Parameter Tuning for Production Implementations
For organizations implementing semantic chunking in production, we recommend the following parameter tuning approach:
- Start with a representative sample of your documents (ideally 50-100 documents across different categories)
- Experiment with different embedding models (balance quality vs. speed based on your requirements)
- Systematically test threshold values across a reasonable range (e.g., 0.3 to 0.8 for cosine_distance)
- Evaluate both structural metrics (chunk sizes, distribution) and retrieval quality for each configuration
- Consider A/B testing in production with a subset of users to validate theoretical findings
Measuring Chunking Success
Beyond retrieval metrics, consider these holistic KPIs:
- End-to-end response relevance: How well does the final generated response address user queries?
- Processing latency: Total processing time from document ingestion to availability for retrieval
- Storage efficiency: Number of chunks and vectors required for effective retrieval
- Cost efficiency: Total token usage for embedding models and vector storage
- Context retention: Whether key information is preserved within individual chunks
Conclusion: Developing a Chunking Strategy
The ideal chunking approach is rarely one-size-fits-all. We recommend:
- Start with a solid baseline.
- Implement proper evaluation metrics beyond just chunk count and size
- Experiment with domain-specific customizations based on your content structure
- Consider computational tradeoffs at your expected document volume
- Re-evaluate regularly as your content and retrieval needs evolve
While our experimental results showed semantic chunking with a significant advantage, it's important to validate these findings within your specific content domain. Chunking strategies can perform differently across various content types, query patterns, and retrieval contexts.
For organizations serious about RAG effectiveness, chunking strategy deserves strategic attention. The right approach can significantly improve retrieval accuracy, reduce costs, and enhance the overall performance of your AI applications.
Want Expert Guidance on Your RAG Implementation?
We can help you design and implement custom RAG strategies tailored to your specific content and use cases. Schedule a consultation to learn how we can help maximize your RAG system's performance.
---