
Executive Summary
For Technical Leadership: 3-Minute Business Overview
Agentic AI represents a fundamental shift from reactive AI tools to autonomous systems that can plan, reason, and execute complex multi-step workflows. Unlike traditional AI that responds to single queries, agentic systems operate continuously, make decisions, and adapt based on outcomes—achieving what Gartner predicts will handle 15% of day-to-day work decisions by 2028 [1].
Key Business Implications:
- Implementation Complexity: Custom development requires significant ML engineering expertise and extended timelines
- Infrastructure Requirements: GPU-intensive workloads with different scaling patterns than traditional web applications
- Team Readiness: Requires specialized skills in ML engineering, prompt engineering, and AI safety practices
- Operational Changes: New monitoring, testing, and quality assurance processes for non-deterministic systems
Critical Architecture Decisions:
- Memory Strategy: Managed vector databases vs. self-hosted solutions (trade-off between cost and control)
- Planning Approach: ReAct (more adaptive, higher compute) vs. Plan-Execute (more predictable resource usage)
- Deployment Model: Container orchestration for control vs. serverless for simplicity
Primary Risk Factors:
- Non-deterministic behavior requires new testing methodologies and quality assurance processes
- Security vulnerabilities from autonomous tool access demand comprehensive guardrails and audit systems
- Scaling economics differ significantly from traditional applications due to GPU and LLM API costs
Immediate Next Steps:
- Proof of Concept: Start with constrained use cases to validate approach before full-scale development
- Vendor Evaluation (see Appendix A): Assess build vs. buy for each component based on team expertise
- Infrastructure Planning: Research actual costs for your scale before committing to architecture decisions
Technical Overview: Understanding Agentic AI Architecture
Agentic AI connects to enterprise data and uses sophisticated reasoning and iterative planning to autonomously solve complex, multi-step problems. Unlike traditional AI models that respond to single queries, agentic AI uses a four-step process for problem-solving: Perceive (gather and process data from various sources), Reason (use large language models as orchestrating reasoning engines), Act (execute actions through tool interfaces), and Learn (adapt based on outcomes).
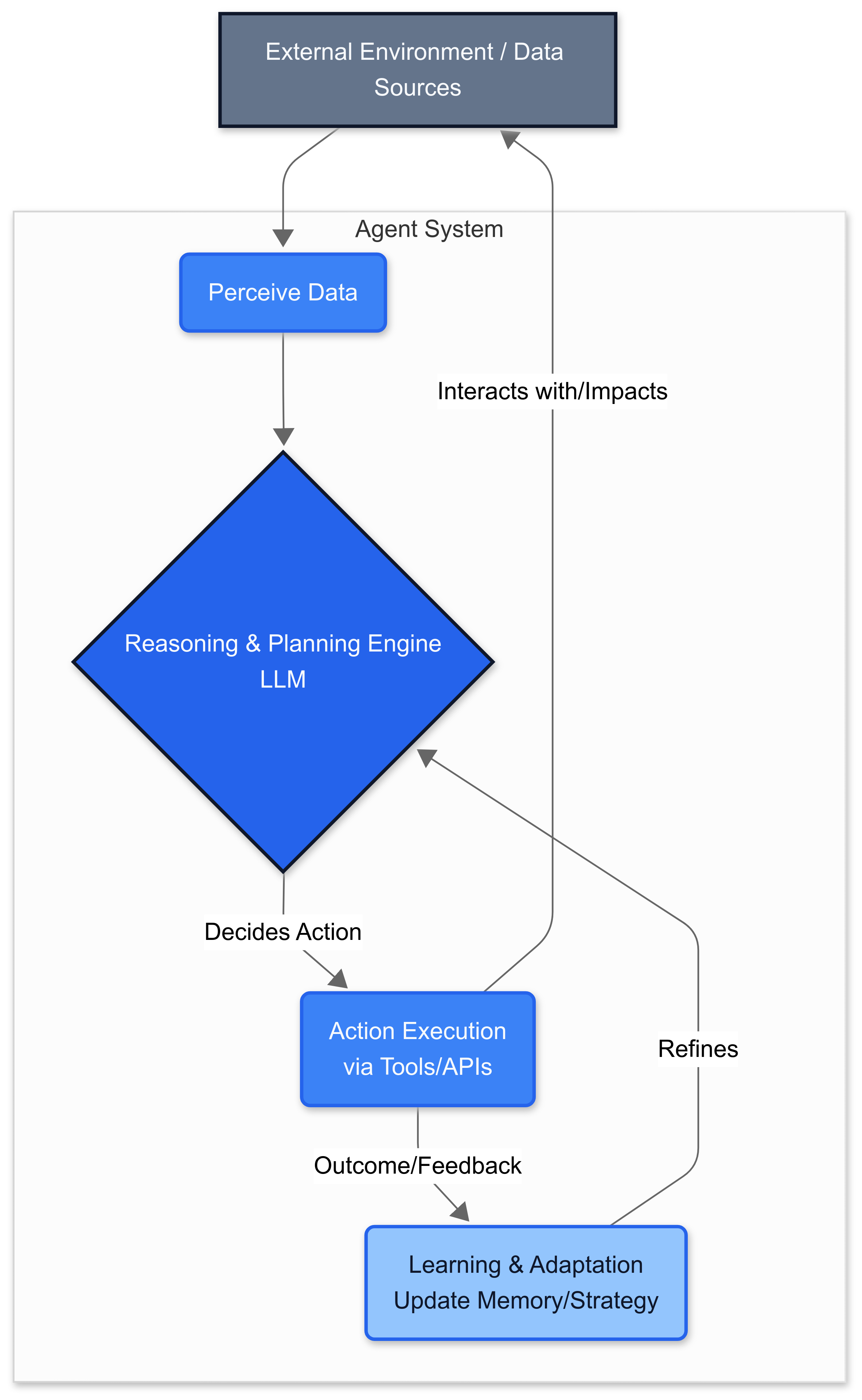
The emergence of agentic AI represents a fundamental shift from stateless AI interactions to persistent, goal-oriented systems that can adapt and learn from their environment.
Defining the Agentic Spectrum
Rather than viewing agency as binary, it exists on a spectrum. Recent research identifies five distinct levels:
- Level 1: Action Automation - Basic text classification and templated responses
- Level 2: Agentic Assistant - Task-specific agents with tool calling capabilities
- Level 3: Plan and Reflect - Systems creating and adjusting plans mid-execution
- Level 4: Autonomous Operations - End-to-end task handling with scenario adaptation
- Level 5: Autonomy - Advanced agents synthesizing solutions for novel problems
Understanding this spectrum helps engineering teams set realistic expectations and choose appropriate implementation approaches for their use cases.
💡 Implementation Insight: Most production systems start at Level 2 (Agentic Assistant) and evolve to Level 3 (Plan and Reflect). Attempting Level 4-5 immediately often leads to project failure due to complexity. Begin with constrained, single-domain agents before expanding scope.
Common Implementation Pitfalls and Technical Debt Scenarios
The Reliability and Predictability Challenge
The way we interact with computers today is predictable. For instance, when we build software systems, an engineer sits and writes code, telling the computer exactly what to do, step by step.
With an agentic AI process, we're not telling the agent what to do step by step. Rather, we lead with the outcome we want to achieve, and the agent determines how to reach this goal. The software agent has a degree of autonomy, which means there can be some randomness in the outputs.
This inherent non-determinism creates significant challenges for software engineering teams accustomed to predictable systems. We'll need to put a similar level of effort into minimizing the randomness of agentic AI systems by making them more predictable and reliable.
Integration Complexity and System Brittleness
The integration of agentic AI with existing systems presents notable technical hurdles. Many legacy systems contain outdated APIs, creating compatibility issues between modern AI solutions and existing software.
Additionally, data formats and communication protocols often clash, requiring significant modifications to achieve seamless operation.
Testing and Regression Challenges
As companies race to implement their initial AI use cases, they're encountering challenges with regression testing and traceability—issues amplified by the non-deterministic nature of generative AI.
Traditional testing methodologies fail when dealing with systems that can produce different valid outputs for the same input.
Data Quality and Management Issues
Too often, generative AI models fail to deliver the expected results because they are disconnected from the most accurate, current data.
Agentic AI systems face additional issues because they will need to access data across a wide variety of different platforms and sources.
🎯 Leadership Takeaway: The biggest implementation failures stem from underestimating testing complexity and data integration challenges. Testing agentic systems requires fundamentally different approaches than traditional software. Consider investing in AI testing expertise and methodologies early in the project lifecycle.
Practical Implementation Architecture
When designing agentic AI systems, software engineers must consider the fundamental software architecture principles known as the "-ilities." In the world of software architecture there are many "-ilities" you must take into consideration with every project. Prioritizing them is necessary because the client will optimistically ask that you do all of them. For agentic AI systems, these quality attributes require specialized consideration due to the autonomous and non-deterministic nature of AI agents.
The 7 Critical "-ilities" for Agentic AI Systems
1. Usability: Human-Agent Interaction Design
Software usability can be described as how effectively end users can use, learn, or control the system. For agentic AI, usability extends beyond traditional UI design to include:
- Agent Transparency: Users must understand what the agent is doing and why
- Control Mechanisms: Clear ways to intervene or override agent decisions
- Feedback Loops: Intuitive methods for users to guide and correct agent behavior
- Trust Indicators: Visual cues showing agent confidence levels and decision rationale
2. Maintainability: Code and Model Management
Maintainability measures how easily code can be changed; flexibility and testability are core factors. Agentic systems require enhanced maintainability practices:
- Model Versioning: Systematic tracking of LLM model updates and prompt iterations
- Agent Behavior Documentation: Clear specifications of expected agent decision patterns
- Modular Architecture: Separating planning, memory, and tool execution components
- Comprehensive Testing: Both deterministic unit tests and stochastic agent behavior validation
3. Scalability: Multi-Agent Coordination
Scalability is the ability for your program to gracefully meet the demand of stress caused by increased usage. Agentic AI scalability involves unique challenges:
- Agent Concurrency: Managing multiple agents operating simultaneously
- Resource Contention: Balancing GPU/CPU allocation across multiple agent processes
- State Synchronization: Coordinating shared memory and knowledge bases
- Load Distribution: Implementing intelligent agent scheduling and workload balancing
4. Availability: Fault-Tolerant Agent Operations
How long the system is up and running and the Mean Time Between Failure (MTBF) is known as the availability of a program. For agentic systems:
- Graceful Degradation: Fallback to simpler decision-making when complex reasoning fails
- Agent Health Monitoring: Real-time tracking of agent performance and decision quality
- Automatic Recovery: Self-healing mechanisms for common failure patterns
- Circuit Breakers: Preventing cascade failures when external tool APIs are unavailable
5. Extensibility: Agent Capability Evolution
Are there points in the system where changes can be made with (or without) program changes? Agentic AI requires dynamic extensibility:
- Tool Integration Framework: Plugin architecture for adding new agent capabilities
- Dynamic Prompt Management: Runtime modification of agent instructions and goals
- Knowledge Base Updates: Hot-swapping of information sources and databases
- Behavior Customization: User-configurable agent personality and decision preferences
6. Security: Autonomous System Protection
Security becomes critical when agents operate autonomously. Security is the measure of system's ability to resist unauthorized attempts at usage or behavior modification, while still providing service to legitimate users:
- Agent Authorization: Strict controls on what actions agents can perform
- Input Validation: Protection against prompt injection and manipulation attacks
- Audit Trails: Comprehensive logging of all agent decisions and actions
- Sandboxed Execution: Isolated environments for agent tool usage
7. Portability: Cross-Platform Agent Deployment
Portability is the ability for your application to run on numerous platforms. For agentic systems:
- Model Agnostic Design: Support for multiple LLM providers and model architectures
- Cloud Provider Independence: Deployment flexibility across AWS, Azure, GCP
- Container-Based Architecture: Docker/Kubernetes compatibility for consistent deployment
- Data Format Standardization: Portable agent memory and knowledge representations
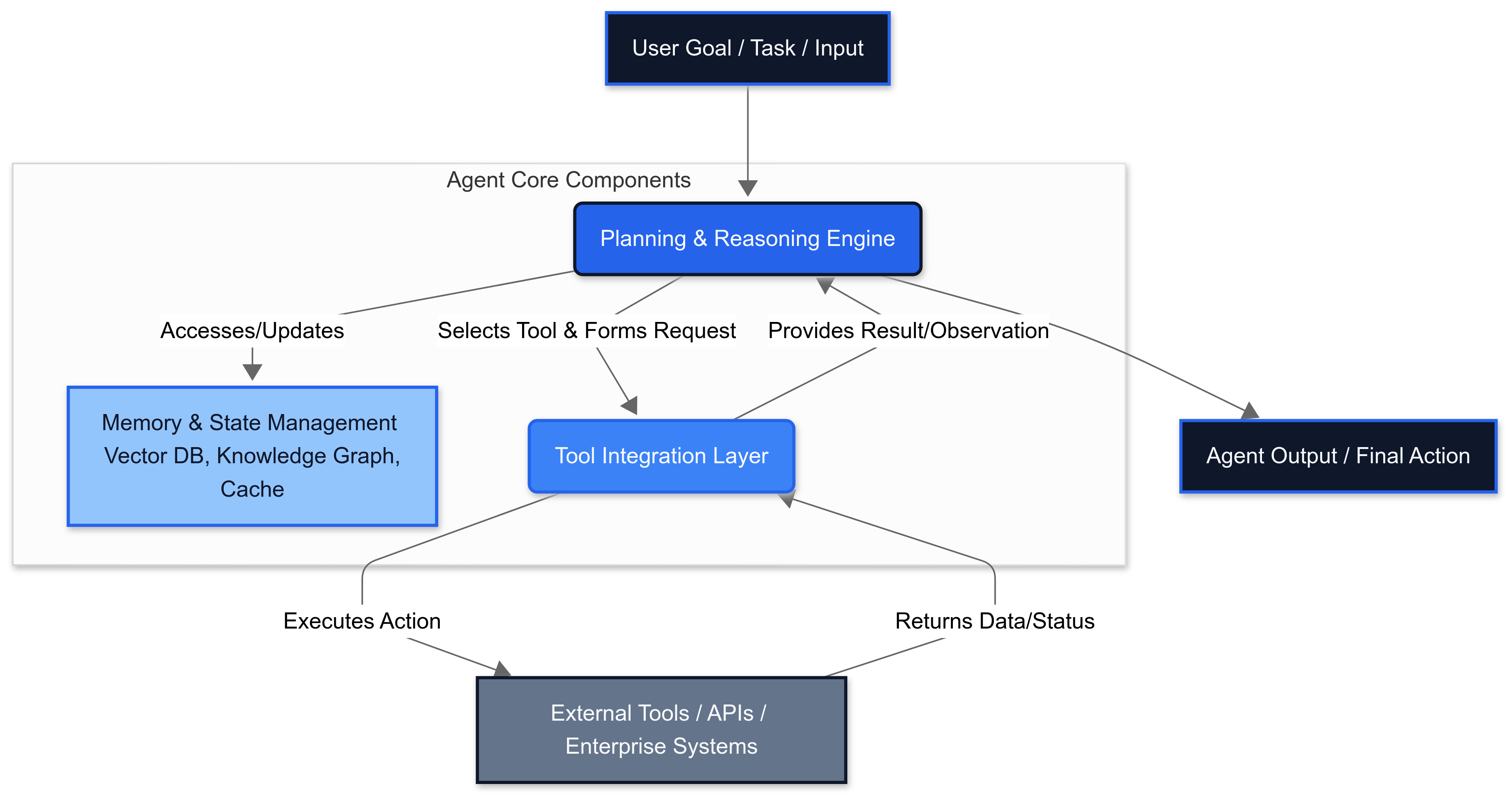
Core Component Architecture
Based on validated implementations and the "-ilities" framework, agentic systems require three fundamental components:
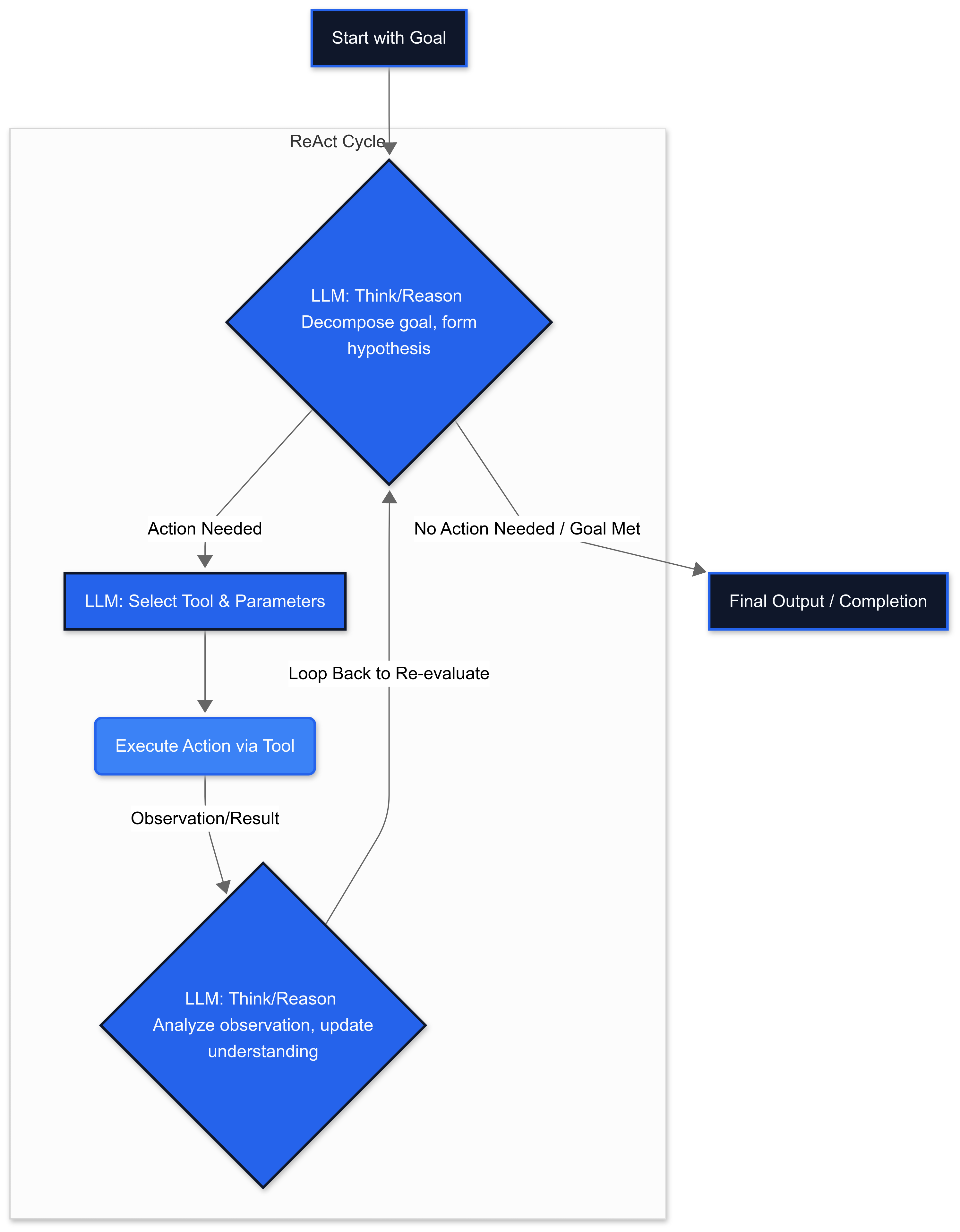
1. Planning and Reasoning Engine
Two dominant patterns emerge from production deployments:
ReAct (Reasoning + Acting)
- Tightly interleaves reasoning and action in synergistic loops
- Higher adaptability but increased computational cost
- Better handling of unexpected outcomes
Plan-and-Execute
- Decouples planning from execution phases
- More cost-effective but less adaptive to changes
- Strategic approach to complex multi-step tasks
2. Tool Integration Layer
Agents rely on external tools—a.k.a. APIs—to execute actions. Reusable APIs will be critical for enabling seamless agentic workflows. Implementation requires:
- Structured function calling interfaces
- Robust error handling for API failures
- Comprehensive authentication and authorization systems
- Security controls preventing tool misuse
3. Memory and State Management
AI agent memory refers to an artificial intelligence (AI) system's ability to store and recall past experiences to improve decision-making, perception and overall performance. Unlike traditional AI models that process each task independently, AI agents with memory can retain context, recognize patterns over time and adapt based on past interactions.
💡 Implementation Insight: The "-ilities" framework provides a systematic approach to avoid common architectural debt. Teams that skip this planning phase often face significant refactoring challenges when scaling beyond initial prototypes. Prioritize Maintainability and Security first, as these are hardest to retrofit later.
Prompt-Orchestration Patterns for Production Systems
Certain prompt engineering patterns have emerged as critical for reliable agentic AI systems. As Anthropic notes in their guide on building effective agents [4], "Consistently, the most successful implementations weren't using complex frameworks or specialized libraries. Instead, they were building with simple, composable patterns."
1. Execution Loop & Run-Loop Prompting
The foundation of agentic behavior is the execution loop pattern. As documented in LangGraph's agentic concepts [5], "In a tool-calling agent, an LLM is called repeatedly in a while-loop. At each step the agent decides which tools to call, and what the inputs to those tools should be."
Run-Loop Controller Implementation
1import json
2from typing import Dict, List
3
4class RunLoopController:
5 """Run-loop prompting with safe exit criteria"""
6
7 def __init__(self, max_iterations: int = 10):
8 self.max_iterations = max_iterations
9 self.loop_template = """
10You are in an execution loop. At each step, you must decide to either:
111. CONTINUE - Take another action toward the goal
122. FINISH - You have completed the task successfully
13
14Current goal: {goal}
15Step: {current_step}/{max_steps}
16Previous actions: {action_history}
17Current observations: {observations}
18
19Think step by step:
201. Have I achieved the goal? If yes, respond with FINISH
212. What is the next logical action? If unclear, respond with FINISH
223. If continuing, specify exactly one action
23
24Response format:
25{{"decision": "CONTINUE|FINISH", "reasoning": "...", "action": "..."}}
26"""
27
28 async def execute_loop(self, goal: str, agent_core) -> Dict:
29 """Execute run-loop with safe termination"""
30
31 action_history = []
32 observations = []
33
34 for step in range(self.max_iterations):
35 prompt = self.loop_template.format(
36 goal=goal,
37 current_step=step + 1,
38 max_steps=self.max_iterations,
39 action_history=action_history[-3:], # Last 3 actions for context
40 observations=observations[-3:]
41 )
42
43 response = await agent_core.llm.generate(prompt)
44
45 try:
46 decision_data = json.loads(response)
47
48 if decision_data.get("decision") == "FINISH":
49 return {
50 "status": "completed",
51 "reason": decision_data.get("reasoning", ""),
52 "total_steps": step + 1
53 }
54 elif decision_data.get("decision") == "CONTINUE":
55 # Execute the specified action
56 action_result = await self._execute_action(
57 decision_data.get("action", ""), agent_core
58 )
59 action_history.append(decision_data.get("action", ""))
60 observations.append(action_result)
61 else:
62 # Invalid decision format - force finish
63 return {"status": "error", "reason": "Invalid decision format"}
64
65 except json.JSONDecodeError:
66 # Parsing failed - force finish for safety
67 return {"status": "error", "reason": "Response parsing failed"}
68
69 # Max iterations reached
70 return {"status": "timeout", "reason": f"Exceeded {self.max_iterations} steps"}
71
72 async def _execute_action(self, action: str, agent_core) -> str:
73 """Execute action via tool registry"""
74 raise NotImplementedError("Connect to ToolRegistry.execute() in production")
752. Input Routing & Semantic Dispatch
For production systems handling diverse queries, input classification and routing are essential. "A router allows an LLM to select a single step from a specified set of options."
Semantic Router Implementation
1import json
2from typing import Dict
3
4class SemanticRouter:
5 """Input classification and dispatch to specialized handlers"""
6
7 def __init__(self):
8 self.routing_template = """
9Classify the user input into exactly one category:
10
11Categories:
12- SUPPORT: Customer service, account issues, troubleshooting
13- CODING: Software development, debugging, technical questions
14- DATA_REQUEST: Information lookup, research, analysis
15- DESTRUCTIVE: Account deletion, data removal, security actions
16- GENERAL: Casual conversation, greetings, unclear requests
17
18User input: "{user_input}"
19
20Response format (JSON only):
21{{`category`: `CATEGORY_NAME`, `confidence`: 0.95, `reasoning`: `brief explanation`}}
22"""
23
24 async def route_request(self, user_input: str, llm_client) -> Dict:
25 """Route user input to appropriate handler"""
26
27 prompt = self.routing_template.format(user_input=user_input)
28 response = await llm_client.generate(prompt)
29
30 try:
31 routing_data = json.loads(response)
32 category = routing_data.get("category", "GENERAL")
33
34 # Route to specialized sub-prompts based on category
35 if category == "SUPPORT":
36 return await self._handle_support_request(user_input, llm_client)
37 elif category == "CODING":
38 return await self._handle_coding_request(user_input, llm_client)
39 elif category == "DESTRUCTIVE":
40 return await self._handle_destructive_request(user_input, llm_client)
41 else:
42 return await self._handle_general_request(user_input, llm_client)
43
44 except json.JSONDecodeError:
45 # Default to general handler if parsing fails
46 return await self._handle_general_request(user_input, llm_client)
47
48 async def _handle_support_request(self, input_text: str, llm_client) -> Dict:
49 """Specialized prompt for customer support scenarios"""
50 support_prompt = f"""
51You are a customer support agent. For this request: "{input_text}"
52
531. Identify the customer's primary issue
542. Suggest up to 3 specific troubleshooting steps
553. Escalate to human if the issue involves: billing, legal, or complex technical problems
56
57Response as JSON: {{"issue_type": "...", "steps": [...], "escalate": boolean}}
58"""
59 response = await llm_client.generate(support_prompt)
60 return {"category": "support", "response": response}
61
62 async def _handle_coding_request(self, input_text: str, llm_client) -> Dict:
63 """Specialized prompt for coding assistance"""
64 # Implementation for coding requests
65 return {"category": "coding", "response": "Coding assistance provided"}
66
67 async def _handle_destructive_request(self, input_text: str, llm_client) -> Dict:
68 """Handle destructive actions with extra validation"""
69 # Implementation with additional safety checks
70 return {"category": "destructive", "response": "Destructive action requires confirmation"}
71
72 async def _handle_general_request(self, input_text: str, llm_client) -> Dict:
73 """Handle general conversations"""
74 # Implementation for general chat
75 return {"category": "general", "response": "General response provided"}
763. Structured Response & JSON Schema Validation
Modern agentic systems require structured outputs for reliable processing. As highlighted by industry best practices, "When working with LLMs, an extremely valuable use case is generating structured data as the output response of the AI prompt."
Structured Response Handler
1import json
2from typing import Dict, List, Optional, Any
3from pydantic import BaseModel, ValidationError
4
5class AgentResponse(BaseModel):
6 """Structured response schema for agent outputs"""
7 action_type: str
8 parameters: Dict[str, Any]
9 confidence: float
10 reasoning: str
11 next_steps: Optional[List[str]] = None
12
13class StructuredResponseHandler:
14 """Enforce JSON schema validation for all agent responses"""
15
16 def __init__(self):
17 self.schema_template = """
18You must respond with valid JSON matching this exact schema:
19{{
20 `action_type`: `string (required)`,
21 `parameters`: {{`key`: `value`}},
22 `confidence`: 0.95,
23 `reasoning`: `string explaining your decision`,
24 `next_steps`: [`optional`, `array`, `of`, `strings`]
25}}
26
27User request: {user_input}
28Available actions: {available_actions}
29
30JSON response:
31"""
32
33 async def get_structured_response(self, user_input: str,
34 available_actions: List[str],
35 llm_client) -> AgentResponse:
36 """Get validated structured response from LLM"""
37
38 prompt = self.schema_template.format(
39 user_input=user_input,
40 available_actions=available_actions
41 )
42
43 max_retries = 3
44 for attempt in range(max_retries):
45 try:
46 response = await llm_client.generate(prompt)
47
48 # Parse and validate against Pydantic schema
49 response_data = json.loads(response)
50 validated_response = AgentResponse(**response_data)
51
52 return validated_response
53
54 except (json.JSONDecodeError, ValidationError) as e:
55 if attempt == max_retries - 1:
56 # Final attempt failed - return safe default
57 return AgentResponse(
58 action_type="error",
59 parameters={"error": str(e)},
60 confidence=0.0,
61 reasoning=f"Failed to parse response after {max_retries} attempts"
62 )
63
64 # Retry with error feedback
65 prompt += f"\n\nPrevious attempt failed with error: {str(e)}. Please provide valid JSON."
664. Prompt Hygiene & Boundary Signaling
Clear prompt structure and boundary markers improve response reliability. Structured syntax: Using an XML-like format, with examples, ensures that tool use is clear and easy to debug.
Prompt Hygiene Implementation
1import json
2from typing import Dict, List, Optional, Any
3
4class PromptHygienizer:
5 """Standardized prompt formatting with clear boundaries"""
6
7 @staticmethod
8 def format_system_prompt(capabilities: List[str], limitations: List[str]) -> str:
9 """Declarative intent with clear capability boundaries"""
10 return f"""
11--- SYSTEM CONTEXT ---
12You are an AI agent with these specific capabilities:
13{chr(10).join('• ' + cap for cap in capabilities)}
14
15Important limitations:
16{chr(10).join('• ' + lim for lim in limitations)}
17
18--- INSTRUCTIONS ---
191. Always operate within your defined capabilities
202. Use structured responses with JSON formatting
213. Explain your reasoning for each decision
224. Request clarification when inputs are ambiguous
23
24--- TOOLS AVAILABLE ---
25Use this exact format for tool calls:
26<tool_name>
27<parameter_name>value</parameter_name>
28</tool_name>
29
30--- RESPONSE FORMAT ---
31Always structure responses as JSON with required fields
32"""
33
34 @staticmethod
35 def format_user_message(user_input: str, context: Dict = None) -> str:
36 """Structured user message with clear boundaries"""
37 formatted_message = f"""
38--- USER REQUEST ---
39{user_input}
40"""
41
42 if context:
43 formatted_message += f"""
44--- CONTEXT ---
45{json.dumps(context, indent=2)}
46"""
47
48 formatted_message += "\n--- AGENT RESPONSE ---\n"
49 return formatted_message
505. Hallucination-Mitigation Hooks
Production agentic systems require multiple layers of validation. Since errors tend to compound as you go down the agent's trajectory, structured outputs and validation are critical.
Hallucination Mitigation System
1import json
2from typing import Dict, List, Optional, Any
3
4class HallucinationMitigation:
5 """Multiple validation layers to catch and correct hallucinations"""
6
7 def __init__(self, knowledge_base, fact_checker):
8 self.knowledge_base = knowledge_base
9 self.fact_checker = fact_checker
10
11 async def validate_response(self, agent_response: str,
12 original_query: str) -> Dict:
13 """Multi-layer validation pipeline"""
14
15 validation_results = {
16 "schema_valid": False,
17 "factually_accurate": False,
18 "contextually_relevant": False,
19 "final_score": 0.0,
20 "corrections": []
21 }
22
23 # Layer 1: Schema validation
24 try:
25 parsed_response = json.loads(agent_response)
26 validation_results["schema_valid"] = True
27 except json.JSONDecodeError:
28 validation_results["corrections"].append("Invalid JSON format")
29 return validation_results
30
31 # Layer 2: Fact checking against knowledge base
32 facts_mentioned = await self._extract_factual_claims(agent_response)
33 fact_accuracy = await self._verify_facts(facts_mentioned)
34 validation_results["factually_accurate"] = fact_accuracy > 0.8
35
36 if not validation_results["factually_accurate"]:
37 validation_results["corrections"].append("Potential factual inaccuracies detected")
38
39 # Layer 3: Relevance check
40 relevance_score = await self._check_relevance(agent_response, original_query)
41 validation_results["contextually_relevant"] = relevance_score > 0.7
42
43 if not validation_results["contextually_relevant"]:
44 validation_results["corrections"].append("Response may be off-topic")
45
46 # Calculate final validation score
47 validation_results["final_score"] = (
48 0.3 * validation_results["schema_valid"] +
49 0.4 * validation_results["factually_accurate"] +
50 0.3 * validation_results["contextually_relevant"]
51 )
52
53 return validation_results
54
55 async def _extract_factual_claims(self, text: str) -> List[str]:
56 """Extract factual claims from text for verification"""
57 # Simplified implementation - use NLP entity extraction in production
58 # Split text into sentences and filter for factual statements
59 sentences = text.split('.')
60 factual_claims = [s.strip() for s in sentences if len(s.strip()) > 10 and any(
61 keyword in s.lower() for keyword in ['is', 'was', 'has', 'can', 'will', 'according to']
62 )]
63 return factual_claims[:5] # Limit to first 5 claims
64
65 async def _check_relevance(self, response: str, query: str) -> float:
66 """Check response relevance to original query"""
67 # Simplified implementation - use semantic similarity in production
68 response_words = set(response.lower().split())
69 query_words = set(query.lower().split())
70
71 if not response_words or not query_words:
72 return 0.0
73
74 overlap = response_words.intersection(query_words)
75 return len(overlap) / len(query_words)
76
77 async def _verify_facts(self, facts: List[str]) -> float:
78 """Verify factual claims against reliable sources"""
79 if not facts:
80 return 1.0
81
82 verified_count = 0
83 for fact in facts:
84 # Check against knowledge base
85 kb_result = await self.knowledge_base.verify_fact(fact)
86 if kb_result.confidence > 0.8:
87 verified_count += 1
88 else:
89 # Secondary check with external fact checker
90 ext_result = await self.fact_checker.verify(fact)
91 if ext_result.verified:
92 verified_count += 1
93
94 return verified_count / len(facts)
95Enhanced Memory and Planning Architecture
Building on the "-ilities" framework and prompt-orchestration patterns, here's a production-ready implementation:
Memory Implementation
Memory Store Architecture
1import json
2from typing import Dict, List, Optional, Any
3from datetime import datetime
4from dataclasses import dataclass
5from abc import ABC, abstractmethod
6
7@dataclass
8class MemoryEntry:
9 """Base memory entry with temporal metadata"""
10 id: str
11 content: Dict
12 timestamp: datetime
13 memory_type: str
14 validity_start: Optional[datetime] = None
15 validity_end: Optional[datetime] = None
16
17class MemoryStore(ABC):
18 """Abstract base class for memory implementations"""
19
20 @abstractmethod
21 async def store(self, entry: MemoryEntry) -> str:
22 pass
23
24 @abstractmethod
25 async def retrieve(self, query: str, limit: int = 10) -> List[MemoryEntry]:
26 pass
27
28 @abstractmethod
29 async def update(self, entry_id: str, content: Dict) -> bool:
30 pass
31
32class VectorMemoryStore(MemoryStore):
33 """Vector database implementation for semantic memory"""
34
35 def __init__(self, vector_db_client, embedding_model):
36 self.client = vector_db_client
37 self.embedding_model = embedding_model
38
39 async def store(self, entry: MemoryEntry) -> str:
40 """Store memory entry with vector embeddings"""
41 embedding = await self.embedding_model.embed(str(entry.content))
42
43 doc = {
44 "id": entry.id,
45 "content": entry.content,
46 "embedding": embedding,
47 "timestamp": entry.timestamp.isoformat(),
48 "memory_type": entry.memory_type,
49 "validity_start": entry.validity_start.isoformat() if entry.validity_start else None,
50 "validity_end": entry.validity_end.isoformat() if entry.validity_end else None
51 }
52
53 await self.client.upsert([doc])
54 return entry.id
55
56 async def retrieve(self, query: str, limit: int = 10) -> List[MemoryEntry]:
57 """Retrieve semantically similar memories"""
58 query_embedding = await self.embedding_model.embed(query)
59
60 results = await self.client.query(
61 vector=query_embedding,
62 top_k=limit,
63 include_metadata=True
64 )
65
66 return [self._deserialize_entry(result) for result in results.matches]
67
68 def _deserialize_entry(self, result) -> MemoryEntry:
69 """Convert database result to MemoryEntry"""
70 metadata = result.metadata
71
72 # Validate required fields exist
73 required_fields = ["id", "content", "timestamp", "memory_type"]
74 for field in required_fields:
75 if field not in metadata:
76 raise ValueError(f"Memory corruption: missing required field '{field}'")
77
78 # Safely parse timestamps with corruption protection
79 try:
80 timestamp = datetime.fromisoformat(metadata["timestamp"])
81 except (ValueError, TypeError) as e:
82 raise ValueError(f"Memory corruption: invalid timestamp format '{metadata['timestamp']}'") from e
83
84 validity_start_str = metadata.get("validity_start")
85 validity_end_str = metadata.get("validity_end")
86
87 validity_start = None
88 validity_end = None
89
90 if validity_start_str:
91 try:
92 validity_start = datetime.fromisoformat(validity_start_str)
93 except (ValueError, TypeError):
94 pass # Invalid format, keep as None
95
96 if validity_end_str:
97 try:
98 validity_end = datetime.fromisoformat(validity_end_str)
99 except (ValueError, TypeError):
100 pass # Invalid format, keep as None
101
102 return MemoryEntry(
103 id=metadata["id"],
104 content=metadata["content"],
105 timestamp=timestamp,
106 memory_type=metadata["memory_type"],
107 validity_start=validity_start,
108 validity_end=validity_end
109 )
110
111
112*For production-ready prompt management and agent orchestration platforms, see Appendix A: Prompt & Agent Framework Tools.*
> 💡 Implementation Insight: These five prompt-orchestration patterns address the majority of production reliability issues. Teams that implement structured response validation and hallucination mitigation from the start report significantly fewer production incidents. The initial engineering investment pays dividends in operational stability.
Planning Engine
Agent Planning Implementation
1import asyncio
2import json
3import logging
4import uuid
5from enum import Enum
6from typing import Any, Dict, List, Optional
7from datetime import datetime
8
9class PlanningMode(Enum):
10 REACT = "react"
11 PLAN_EXECUTE = "plan_execute"
12
13class AgentAction:
14 """Represents an action the agent can take"""
15 def __init__(self, tool_name: str, parameters: Dict[str, Any], reasoning: str = ""):
16 self.tool_name = tool_name
17 self.parameters = parameters
18 self.reasoning = reasoning
19 self.result: Optional[Any] = None
20 self.error: Optional[str] = None
21
22class AgentPlan:
23 """Represents a multi-step plan"""
24 def __init__(self, goal: str, steps: List[str]):
25 self.goal = goal
26 self.steps = steps
27 self.current_step = 0
28 self.completed_steps: List[bool] = [False] * len(steps)
29
30class AgentPlanner:
31 """Core planning and reasoning engine"""
32
33 def __init__(self, llm_client, tool_registry, memory_store, mode: PlanningMode = PlanningMode.REACT):
34 self.llm = llm_client
35 self.tools = tool_registry
36 self.memory = memory_store
37 self.mode = mode
38 self.logger = logging.getLogger(__name__)
39
40 async def execute_goal(self, goal: str, max_iterations: int = 10) -> Dict[str, Any]:
41 """Execute a goal using the configured planning mode"""
42
43 if self.mode == PlanningMode.REACT:
44 return await self._execute_react(goal, max_iterations)
45 else:
46 return await self._execute_plan_and_execute(goal)
47
48 def _parse_action(self, action_text: str) -> Optional[AgentAction]:
49 """Parse LLM response into structured action"""
50 if ":" in action_text and "{" in action_text:
51 try:
52 parts = action_text.split(":", 1)
53 tool_name = parts[0].strip()
54 params_str = parts[1].strip()
55
56 # Use JSON parsing instead of eval for security
57 try:
58 parameters = json.loads(params_str)
59 except json.JSONDecodeError:
60 # Fallback for simple parameter strings
61 parameters = {"input": params_str}
62
63 return AgentAction(tool_name, parameters)
64 except Exception as e:
65 self.logger.error(f"Failed to parse action: {e}")
66 return None
67
68 async def _execute_react(self, goal: str, max_iterations: int) -> Dict[str, Any]:
69 """ReAct implementation: interleaved reasoning and acting"""
70
71 context = {"goal": goal, "observations": [], "actions": [], "thoughts": []}
72
73 for iteration in range(max_iterations):
74 # Retrieve relevant memories
75 relevant_memories = await self.memory.retrieve(goal, limit=5)
76 context["memories"] = [mem.content for mem in relevant_memories]
77
78 # Generate reasoning
79 thought_prompt = self._build_react_prompt(context, "thought")
80 thought = await self.llm.generate(thought_prompt)
81 context["thoughts"].append(thought)
82
83 # Determine if action is needed
84 action_prompt = self._build_react_prompt(context, "action")
85 action_response = await self.llm.generate(action_prompt)
86
87 if "FINISH" in action_response:
88 break
89
90 # Parse and execute action
91 action = self._parse_action(action_response)
92 if action:
93 try:
94 result = await self.tools.execute(action.tool_name, action.parameters)
95 action.result = result
96 context["actions"].append(action)
97 context["observations"].append(result)
98
99 # Store experience in memory
100 await self._store_experience(goal, action, result)
101
102 except Exception as e:
103 action.error = str(e)
104 context["observations"].append(f"Error: {e}")
105 self.logger.error(f"Action execution failed: {e}")
106
107 return {
108 "success": "FINISH" in action_response if 'action_response' in locals() else False,
109 "context": context,
110 "iterations": iteration + 1
111 }
112
113 def _build_react_prompt(self, context: Dict, prompt_type: str) -> str:
114 """Build ReAct-style prompts for reasoning"""
115 base_context = f"""
116 Goal: {context['goal']}
117 Previous thoughts: {context['thoughts'][-3:] if context['thoughts'] else 'None'}
118 Previous actions: {[a.tool_name for a in context['actions'][-3:]] if context['actions'] else 'None'}
119 Recent observations: {context['observations'][-3:] if context['observations'] else 'None'}
120 Relevant memories: {context.get('memories', [])}
121 """
122
123 if prompt_type == "thought":
124 return base_context + "\nThought: What should I consider next?"
125 elif prompt_type == "action":
126 return base_context + f"\nAvailable tools: {list(self.tools.list_tools())}\nAction: (tool_name: parameters) or FINISH"
127
128 async def _store_experience(self, goal: str, action: AgentAction, result: Any):
129 """Store successful experiences in memory"""
130 experience = MemoryEntry(
131 id=str(uuid.uuid4()),
132 content={
133 "goal": goal,
134 "action": action.tool_name,
135 "parameters": action.parameters,
136 "result": str(result)[:1000], # Truncate long results
137 "success": action.error is None
138 },
139 timestamp=datetime.now(),
140 memory_type="episodic"
141 )
142 await self.memory.store(experience)
143Agent Health Monitoring
Health Monitoring System
1import logging
2from typing import Dict, List, Optional, Any
3from datetime import datetime
4
5class AgentHealthMonitor:
6 """Availability: Health monitoring and fault tolerance for agent systems"""
7
8 def __init__(self, alert_thresholds: Dict[str, float]):
9 self.alert_thresholds = alert_thresholds
10 self.agent_health_data = {}
11 self.circuit_breakers = {}
12
13 async def monitor_agent_health(self, agent_id: str, execution_metrics: Dict):
14 """Monitor agent performance and trigger alerts for degradation"""
15
16 health_score = self._calculate_health_score(execution_metrics)
17 self.agent_health_data[agent_id] = {
18 "health_score": health_score,
19 "last_check": datetime.now(),
20 "metrics": execution_metrics
21 }
22
23 # Check for health degradation
24 if health_score < self.alert_thresholds["critical_health"]:
25 await self._trigger_health_alert(agent_id, "critical", health_score)
26 await self._initiate_recovery_procedure(agent_id)
27 elif health_score < self.alert_thresholds["warning_health"]:
28 await self._trigger_health_alert(agent_id, "warning", health_score)
29
30 def _calculate_health_score(self, metrics: Dict) -> float:
31 """Calculate composite health score from multiple metrics
32
33 Weights based on SRE best practices:
34 - Success rate: 40% (primary indicator of agent effectiveness)
35 - Response latency: 30% (user experience impact)
36 - Error rate: 20% (system reliability)
37 - Resource usage: 10% (operational efficiency)
38 """
39 weights = {
40 "success_rate": 0.4,
41 "response_latency": 0.3,
42 "error_rate": 0.2,
43 "resource_usage": 0.1
44 }
45
46 # Normalize metrics to 0-1 scale
47 normalized_success = metrics.get("success_rate", 0.5)
48 normalized_latency = max(0, 1 - (metrics.get("avg_latency_ms", 1000) / 5000))
49 normalized_errors = max(0, 1 - metrics.get("error_rate", 0.5))
50 normalized_resources = max(0, 1 - metrics.get("cpu_usage", 0.5))
51
52 health_score = (
53 weights["success_rate"] * normalized_success +
54 weights["response_latency"] * normalized_latency +
55 weights["error_rate"] * normalized_errors +
56 weights["resource_usage"] * normalized_resources
57 )
58
59 return health_score
60
61 async def _trigger_health_alert(self, agent_id: str, severity: str, score: float):
62 """Trigger health alert notification"""
63 # Implementation for alert system integration
64 pass
65
66 async def _initiate_recovery_procedure(self, agent_id: str):
67 """Availability: Automatic recovery mechanisms"""
68 # Implement graceful degradation
69 await self._enable_simple_mode(agent_id)
70 # Restart agent with basic configuration
71 await self._restart_agent_safely(agent_id)
72
73 async def _enable_simple_mode(self, agent_id: str):
74 """Enable simplified operation mode"""
75 # Implementation for fallback mode
76 pass
77
78 async def _restart_agent_safely(self, agent_id: str):
79 """Safe agent restart procedure"""
80 # Implementation for safe restart
81 pass
82
83
84*For AI-specific health monitoring and reliability platforms, see Appendix A: Health Monitoring & Reliability Tools.*
Tool Registry & Security
Secure Tool Registry
1import logging
2from typing import Dict, List, Optional, Any, Callable
3
4class ExtensibleToolRegistry:
5 """Extensibility: Dynamic tool integration for agents"""
6
7 def __init__(self):
8 self.tools = {}
9 self.tool_schemas = {}
10 self.security_policies = {}
11
12 def register_tool(self, tool_name: str, tool_impl: Callable,
13 schema: Dict, security_policy: Dict):
14 """Extensibility: Register new tools at runtime"""
15
16 # Validate tool implementation
17 if not self._validate_tool_interface(tool_impl):
18 raise ValueError(f"Tool {tool_name} does not implement required interface")
19
20 # Security: Apply access controls
21 if not self._validate_security_policy(security_policy):
22 raise ValueError(f"Invalid security policy for tool {tool_name}")
23
24 self.tools[tool_name] = tool_impl
25 self.tool_schemas[tool_name] = schema
26 self.security_policies[tool_name] = security_policy
27
28 logging.info(f"Registered new tool: {tool_name}")
29
30 async def execute(self, tool_name: str, parameters: Dict,
31 agent_id: str = None, context: Dict = None) -> Any:
32 """Security: Controlled tool execution with authorization"""
33
34 # Security: Verify agent authorization
35 if agent_id and not self._check_agent_authorization(agent_id, tool_name):
36 raise PermissionError(f"Agent {agent_id} not authorized for tool {tool_name}")
37
38 # Security: Validate input parameters
39 if not self._validate_parameters(tool_name, parameters):
40 raise ValueError(f"Invalid parameters for tool {tool_name}")
41
42 # Execute with sandboxing
43 try:
44 result = await self._execute_sandboxed(tool_name, parameters, context or {})
45
46 # Audit logging for security
47 await self._log_tool_execution(agent_id, tool_name, parameters, result)
48
49 return result
50
51 except Exception as e:
52 # Security: Log potential security violations
53 await self._log_security_event(agent_id, tool_name, str(e))
54 raise
55
56 def list_tools(self) -> List[str]:
57 """Return list of available tools"""
58 return list(self.tools.keys())
59
60 def _validate_tool_interface(self, tool_impl: Callable) -> bool:
61 """Maintainability: Ensure consistent tool interfaces"""
62 # Check for required methods and signatures
63 required_methods = ["execute", "validate_input", "get_schema"]
64 return all(hasattr(tool_impl, method) for method in required_methods)
65
66 def _validate_security_policy(self, policy: Dict) -> bool:
67 """Validate security policy structure"""
68 required_fields = ["allowed_agents", "rate_limit", "audit_level"]
69 return all(field in policy for field in required_fields)
70
71 def _check_agent_authorization(self, agent_id: str, tool_name: str) -> bool:
72 """Check if agent is authorized to use tool"""
73 policy = self.security_policies.get(tool_name, {})
74 allowed_agents = policy.get("allowed_agents", [])
75 return "*" in allowed_agents or agent_id in allowed_agents
76
77 def _validate_parameters(self, tool_name: str, parameters: Dict) -> bool:
78 """Validate parameters against tool schema"""
79 schema = self.tool_schemas.get(tool_name, {})
80 # Simplified validation - use proper JSON schema validation in production
81 required_params = schema.get("required", [])
82 return all(param in parameters for param in required_params)
83
84 async def _execute_sandboxed(self, tool_name: str, parameters: Dict, context: Dict) -> Any:
85 """Execute tool in sandboxed environment"""
86 tool = self.tools[tool_name]
87 return await tool.execute(parameters, context)
88
89 async def _log_tool_execution(self, agent_id: str, tool_name: str, parameters: Dict, result: Any):
90 """Log tool execution for audit trail"""
91 # Implementation for audit logging
92 pass
93
94 async def _log_security_event(self, agent_id: str, tool_name: str, error: str):
95 """Log security-related events"""
96 # Implementation for security event logging
97 pass
98
99
100*For API gateway, integration platforms, and security tools, see Appendix A: Tool Integration & API Management.*
Benchmarking and Performance Evaluation
Established Benchmarking Frameworks
For rigorous assessment of agentic AI systems, leverage these validated benchmarks:
SWE-bench for Code Generation Capabilities
SWE-bench measures AI agents' capability to resolve GitHub issues [9]. The benchmark utilizes GitHub as a rich resource of Python software bugs across 16 repositories and provides a mechanism for measuring how well the LLM-based AI agents can solve them.
Current performance shows significant improvement: Today, the SWE-bench leaderboard shows the top-scoring model resolved 55% of the coding issues on SWE-bench Lite, which is a subset of the benchmark designed to make evaluation less costly and more accessible.
AgentBench for Multi-Domain Evaluation
AgentBench is a comprehensive benchmark designed to evaluate LLMs as agents in interactive environments [10]. It currently consists of eight distinct environments, each representing different scenarios including SQL-based environments, game-based environments, and web-based environments for shopping and browsing.
τ-Bench for Real-World Dynamic Interactions
Drawing on experience with live agents in production, τ-bench tests an agent's ability to follow rules, reason, remember information over long and complex contexts, and communicate effectively in realistic conversations [11].
Key Performance Metrics
Based on production deployments, track these validated metrics:
System Performance Metrics:
- Task completion rate and accuracy
- Response latency (P50, P95, P99)
- Resource utilization (CPU, GPU, memory)
- API call efficiency and error rates
Agentic-Specific Metrics:
- Autonomy level (frequency of human interventions required)
- Goal achievement rate across different complexity levels
- Adaptability score (consistency across scenario variations)
- Tool selection accuracy and parameter quality
Production Quality Metrics:
- pass@k: measures the probability an agent succeeds at least once in k attempts
- Context adherence and memory utilization
- Safety guardrail effectiveness and false positive rates
Benchmarking Implementation
1import asyncio
2import time
3import statistics
4from typing import Dict, List, Tuple, Optional, Any
5from dataclasses import dataclass
6
7@dataclass
8class BenchmarkResult:
9 """Individual benchmark test result"""
10 test_id: str
11 success: bool
12 latency_ms: float
13 accuracy_score: float
14 error_message: Optional[str] = None
15
16class AgentBenchmarkSuite:
17 """Comprehensive benchmarking suite for agentic AI systems"""
18
19 def __init__(self, agent, test_cases: List[Dict]):
20 self.agent = agent
21 self.test_cases = test_cases
22
23 async def run_benchmark(self, iterations: int = 3) -> Dict[str, any]:
24 """Run comprehensive benchmark suite"""
25
26 results = []
27
28 for test_case in self.test_cases:
29 test_results = []
30
31 # Run each test multiple times for reliability measurement
32 for iteration in range(iterations):
33 result = await self._run_single_test(test_case, iteration)
34 test_results.append(result)
35
36 results.extend(test_results)
37
38 return self._analyze_results(results)
39
40 async def _run_single_test(self, test_case: Dict, iteration: int) -> BenchmarkResult:
41 """Execute a single benchmark test"""
42
43 test_id = f"{test_case['id']}_iter_{iteration}"
44 start_time = time.time()
45
46 try:
47 # Execute agent task
48 result = await self.agent.execute_goal(
49 goal=test_case['goal'],
50 max_iterations=test_case.get('max_iterations', 10)
51 )
52
53 latency = (time.time() - start_time) * 1000
54
55 # Evaluate result quality
56 accuracy = self._evaluate_accuracy(result, test_case['expected'])
57 success = accuracy >= test_case.get('success_threshold', 0.8)
58
59 return BenchmarkResult(
60 test_id=test_id,
61 success=success,
62 latency_ms=latency,
63 accuracy_score=accuracy
64 )
65
66 except Exception as e:
67 return BenchmarkResult(
68 test_id=test_id,
69 success=False,
70 latency_ms=(time.time() - start_time) * 1000,
71 accuracy_score=0.0,
72 error_message=str(e)
73 )
74
75 def _evaluate_accuracy(self, actual_result: Dict, expected_result: Dict) -> float:
76 """Evaluate accuracy of agent result against expected outcome"""
77
78 if not actual_result.get('success', False):
79 return 0.0
80
81 # Compare key metrics based on test type
82 accuracy_scores = []
83
84 # Goal completion accuracy
85 if 'goal_completed' in expected_result:
86 goal_score = 1.0 if actual_result.get('success') == expected_result['goal_completed'] else 0.0
87 accuracy_scores.append(goal_score)
88
89 # Output quality assessment
90 if 'expected_output' in expected_result:
91 output_similarity = self._calculate_similarity(
92 actual_result.get('final_output', ''),
93 expected_result['expected_output']
94 )
95 accuracy_scores.append(output_similarity)
96
97 # Tool usage accuracy
98 if 'expected_tools' in expected_result:
99 tools_used = set(action.tool_name for action in actual_result.get('context', {}).get('actions', []))
100 expected_tools = set(expected_result['expected_tools'])
101 tool_accuracy = len(tools_used.intersection(expected_tools)) / len(expected_tools) if expected_tools else 1.0
102 accuracy_scores.append(tool_accuracy)
103
104 return statistics.mean(accuracy_scores) if accuracy_scores else 0.0
105
106 def _calculate_similarity(self, text1: str, text2: str) -> float:
107 """Calculate semantic similarity between texts"""
108 # Simplified implementation - use proper semantic similarity in production
109 words1 = set(text1.lower().split())
110 words2 = set(text2.lower().split())
111
112 if not words1 and not words2:
113 return 1.0
114 if not words1 or not words2:
115 return 0.0
116
117 intersection = words1.intersection(words2)
118 union = words1.union(words2)
119
120 return len(intersection) / len(union)
121
122 def _analyze_results(self, results: List[BenchmarkResult]) -> Dict[str, any]:
123 """Analyze benchmark results and generate comprehensive report"""
124
125 successful_results = [r for r in results if r.success]
126
127 # Basic statistics
128 success_rate = len(successful_results) / len(results) if results else 0.0
129 avg_latency = statistics.mean([r.latency_ms for r in results]) if results else 0.0
130 p95_latency = statistics.quantiles([r.latency_ms for r in results], n=20)[18] if len(results) >= 20 else 0.0
131 avg_accuracy = statistics.mean([r.accuracy_score for r in successful_results]) if successful_results else 0.0
132
133 # Reliability metrics
134 pass_at_k_scores = self._calculate_pass_at_k(results)
135
136 # Error analysis
137 error_types = {}
138 for result in results:
139 if not result.success and result.error_message:
140 error_type = result.error_message.split(':')[0]
141 error_types[error_type] = error_types.get(error_type, 0) + 1
142
143 return {
144 "overall_metrics": {
145 "success_rate": success_rate,
146 "average_latency_ms": avg_latency,
147 "p95_latency_ms": p95_latency,
148 "average_accuracy": avg_accuracy,
149 "total_tests": len(results),
150 "successful_tests": len(successful_results)
151 },
152 "reliability_metrics": {
153 "pass_at_1": pass_at_k_scores.get(1, 0.0),
154 "pass_at_3": pass_at_k_scores.get(3, 0.0),
155 "pass_at_5": pass_at_k_scores.get(5, 0.0)
156 },
157 "error_analysis": error_types,
158 "detailed_results": [
159 {
160 "test_id": r.test_id,
161 "success": r.success,
162 "latency_ms": r.latency_ms,
163 "accuracy": r.accuracy_score,
164 "error": r.error_message
165 }
166 for r in results
167 ]
168 }
169
170 def _calculate_pass_at_k(self, results: List[BenchmarkResult]) -> Dict[int, float]:
171 """Calculate pass@k metrics for reliability assessment"""
172
173 # Group results by test case
174 test_groups = {}
175 for result in results:
176 test_base = result.test_id.split('_iter_')[0]
177 if test_base not in test_groups:
178 test_groups[test_base] = []
179 test_groups[test_base].append(result.success)
180
181 pass_at_k = {}
182 for k in [1, 3, 5]:
183 if k <= min(len(group) for group in test_groups.values()):
184 successes = 0
185 total = 0
186
187 for group in test_groups.values():
188 # Check if at least one of first k attempts succeeded
189 if any(group[:k]):
190 successes += 1
191 total += 1
192
193 pass_at_k[k] = successes / total if total > 0 else 0.0
194
195 return pass_at_k
196Performance and Scalability Impact Analysis
Computational Requirements and Infrastructure Costs
GPU hourly rates change fast. As a rule of thumb today (mid-2025):
- H100s cost ~3× A100s on-demand.
- Spot/Preemptible discounts often slash 70–90 % if your workload is fault-tolerant.
- Inference throughput scales sub-linearly; optimised servers like vLLM deliver 2–4× more requests per GPU than naïve loops.
💡 Check current prices: AWS Pricing API or cloud-gpus.com before committing to an architecture.
Latency and Response Time Considerations
Guardrails, additional model hops, and sequential tool calls each introduce latency. In test setups, a single safety layer can add hundreds of milliseconds; stacking several guardrails or multi-agent chains can push end-user latency well past the 1-second mark.
The cumulative effect of multiple agent interactions and sequential guardrail evaluations can significantly impact system performance, requiring careful latency budgeting and optimization.
API Rate Limiting and Throttling
AI-related traffic across the Postman platform has increased by nearly 73% in 2024, highlighting the growing demand on API infrastructure. Engineering teams must implement robust rate limiting and throttling mechanisms to handle the increased load from autonomous agent operations.
Infrastructure Considerations
Cloud vs On-Premises Deployment
The choice between cloud and on-premises deployment significantly impacts agentic AI system architecture:
Cloud Advantages:
- Scalable GPU resources (vLLM and TGI serve thousands of requests/second per GPU)
- Managed services for vector databases and LLM APIs
- Automatic scaling for varying computational demands
- Lower upfront infrastructure costs
On-Premises Considerations:
- Data sovereignty and security requirements
- Reduced API latency for internal operations
- Higher upfront costs but predictable ongoing expenses
- Greater control over infrastructure and security
Memory Architecture Scaling: Vector databases and knowledge graphs require significant memory allocation:
- Vector stores: 1-4GB per million embeddings for uncompressed 768-dim float32 vectors
- With compression: Product Quantization (PQ) and Binary Quantization (BQ) can reduce memory usage by 4-8×
- HNSW indices: Memory requirements follow formula: 1.1 × (4 × dimensions + 8 × M) × num_vectors bytes (M = max links per node, default 16)
- Caching layers: Allocate 20-30% of total memory for frequently accessed data
Note: Compression techniques like PQ offer up to 90% memory reduction compared to uncompressed vectors, while scalar quantization provides 75% reduction with minimal impact on accuracy.
Configuration Examples
Docker Compose for Development Environment
Development Docker Configuration
1version: '3.8'
2services:
3 agentic-ai-app:
4 build: .
5 ports:
6 - "8000:8000"
7 environment:
8 - OPENAI_API_KEY=${OPENAI_API_KEY}
9 - VECTOR_DB_URL=http://weaviate:8080
10 - GRAPH_DB_URL=bolt://neo4j:7687
11 - REDIS_URL=redis://redis:6379
12 depends_on:
13 - weaviate
14 - neo4j
15 - redis
16 volumes:
17 - ./config:/app/config
18 - ./logs:/app/logs
19
20 weaviate:
21 image: semitechnologies/weaviate:1.22.4
22 ports:
23 - "8080:8080"
24 environment:
25 QUERY_DEFAULTS_LIMIT: 25
26 AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
27 PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
28 DEFAULT_VECTORIZER_MODULE: 'none'
29 ENABLE_MODULES: 'text2vec-openai'
30 volumes:
31 - weaviate_data:/var/lib/weaviate
32
33 neo4j:
34 image: neo4j:5.13
35 ports:
36 - "7474:7474"
37 - "7687:7687"
38 environment:
39 NEO4J_AUTH: neo4j/password
40 NEO4J_PLUGINS: '["apoc"]'
41 NEO4J_apoc_export_file_enabled: true
42 NEO4J_apoc_import_file_enabled: true
43 volumes:
44 - neo4j_data:/data
45 - neo4j_logs:/logs
46
47 redis:
48 image: redis:7.2-alpine
49 ports:
50 - "6379:6379"
51 volumes:
52 - redis_data:/data
53 command: redis-server --appendonly yes
54
55volumes:
56 weaviate_data:
57 neo4j_data:
58 neo4j_logs:
59 redis_data:
60Kubernetes Production Deployment
Production Kubernetes Configuration
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: agentic-ai-deployment
5 labels:
6 app: agentic-ai
7spec:
8 replicas: 3
9 selector:
10 matchLabels:
11 app: agentic-ai
12 template:
13 metadata:
14 labels:
15 app: agentic-ai
16 spec:
17 containers:
18 - name: agentic-ai
19 image: your-registry/agentic-ai:latest
20 ports:
21 - containerPort: 8000
22 env:
23 - name: OPENAI_API_KEY
24 valueFrom:
25 secretKeyRef:
26 name: ai-secrets
27 key: openai-api-key
28 - name: VECTOR_DB_URL
29 value: "http://weaviate-service:8080"
30 - name: GRAPH_DB_URL
31 value: "bolt://neo4j-service:7687"
32 resources:
33 requests:
34 cpu: 1000m
35 memory: 2Gi
36 limits:
37 cpu: 2000m
38 memory: 4Gi
39 livenessProbe:
40 httpGet:
41 path: /health
42 port: 8000
43 initialDelaySeconds: 30
44 periodSeconds: 10
45 readinessProbe:
46 httpGet:
47 path: /ready
48 port: 8000
49 initialDelaySeconds: 5
50 periodSeconds: 5
51
52---
53apiVersion: v1
54kind: Service
55metadata:
56 name: agentic-ai-service
57spec:
58 selector:
59 app: agentic-ai
60 ports:
61 - protocol: TCP
62 port: 80
63 targetPort: 8000
64 type: LoadBalancer
65
66---
67apiVersion: autoscaling/v2
68kind: HorizontalPodAutoscaler
69metadata:
70 name: agentic-ai-hpa
71spec:
72 scaleTargetRef:
73 apiVersion: apps/v1
74 kind: Deployment
75 name: agentic-ai-deployment
76 minReplicas: 3
77 maxReplicas: 20
78 metrics:
79 - type: Resource
80 resource:
81 name: cpu
82 target:
83 type: Utilization
84 averageUtilization: 70
85 - type: Resource
86 resource:
87 name: memory
88 target:
89 type: Utilization
90 averageUtilization: 80
91Technical Monitoring and Observability
Essential Observability Stack
Based on production deployments, implement comprehensive monitoring across these dimensions:
Application Performance Monitoring:
- Response latency tracking (P50, P95, P99)
- Request throughput and error rates
- Resource utilization (CPU, memory, GPU)
- Agent execution traces and decision paths
AI-Specific Metrics:
- LLM API call latency and token usage
- Tool execution success rates and timing
- Memory retrieval accuracy and latency
- Guardrail evaluation performance
Monitoring Implementation
1import time
2import asyncio
3import json
4import logging
5from typing import Dict, Any, Optional, List
6from dataclasses import dataclass, asdict
7from contextlib import asynccontextmanager
8from datetime import datetime
9
10@dataclass
11class AgentMetrics:
12 """Core metrics for agent performance tracking"""
13 agent_id: str
14 goal: str
15 execution_time_ms: float
16 success: bool
17 iterations: int
18 tools_used: int
19 memory_retrievals: int
20 tokens_consumed: int
21 error_message: Optional[str] = None
22
23@dataclass
24class GuardrailMetrics:
25 """Metrics for guardrail performance"""
26 guardrail_name: str
27 evaluation_time_ms: float
28 allowed: bool
29 confidence: float
30 input_length: int
31
32class MetricsCollector:
33 """Centralized metrics collection and reporting"""
34
35 def __init__(self, metrics_backend='prometheus'):
36 self.backend = metrics_backend
37 self.logger = logging.getLogger(__name__)
38 self.metrics_buffer = []
39
40 async def record_agent_execution(self, metrics: AgentMetrics):
41 """Record agent execution metrics"""
42
43 # Add timestamp
44 metric_data = {
45 **asdict(metrics),
46 'timestamp': time.time(),
47 'metric_type': 'agent_execution'
48 }
49
50 self.metrics_buffer.append(metric_data)
51
52 # Log for immediate visibility
53 self.logger.info(f"Agent {metrics.agent_id} completed in {metrics.execution_time_ms:.2f}ms, "
54 f"success={metrics.success}, iterations={metrics.iterations}")
55
56 async def record_guardrail_evaluation(self, metrics: GuardrailMetrics):
57 """Record guardrail evaluation metrics"""
58
59 metric_data = {
60 **asdict(metrics),
61 'timestamp': time.time(),
62 'metric_type': 'guardrail_evaluation'
63 }
64
65 self.metrics_buffer.append(metric_data)
66
67 if not metrics.allowed:
68 self.logger.warning(f"Guardrail {metrics.guardrail_name} blocked input "
69 f"(confidence: {metrics.confidence:.3f})")
70
71 async def flush_metrics(self):
72 """Flush metrics to backend storage"""
73
74 if not self.metrics_buffer:
75 return
76
77 try:
78 # Implementation depends on backend (Prometheus, CloudWatch, etc.)
79 if self.backend == 'prometheus':
80 await self._flush_to_prometheus()
81 elif self.backend == 'cloudwatch':
82 await self._flush_to_cloudwatch()
83 else:
84 # Default: log to structured logs
85 for metric in self.metrics_buffer:
86 self.logger.info(f"METRIC: {json.dumps(metric)}")
87
88 self.metrics_buffer.clear()
89
90 except Exception as e:
91 self.logger.error(f"Failed to flush metrics: {e}")
92
93 async def _flush_to_prometheus(self):
94 """Flush metrics to Prometheus"""
95 # Implementation for Prometheus push gateway
96 pass
97
98 async def _flush_to_cloudwatch(self):
99 """Flush metrics to AWS CloudWatch"""
100 # Implementation for CloudWatch custom metrics
101 pass
102
103@asynccontextmanager
104async def monitor_agent_execution(collector: MetricsCollector, agent_id: str, goal: str):
105 """Context manager for monitoring agent execution"""
106
107 start_time = time.time()
108 metrics = AgentMetrics(
109 agent_id=agent_id,
110 goal=goal,
111 execution_time_ms=0.0,
112 success=False,
113 iterations=0,
114 tools_used=0,
115 memory_retrievals=0,
116 tokens_consumed=0
117 )
118
119 try:
120 yield metrics
121 metrics.success = True
122
123 except Exception as e:
124 metrics.error_message = str(e)
125 raise
126
127 finally:
128 metrics.execution_time_ms = (time.time() - start_time) * 1000
129 await collector.record_agent_execution(metrics)
130
131# Example usage in agent implementation
132async def monitored_agent_execution(agent, goal: str, collector: MetricsCollector):
133 """Example of monitored agent execution"""
134
135 async with monitor_agent_execution(collector, agent.id, goal) as metrics:
136 result = await agent.execute_goal(goal)
137
138 # Update metrics based on execution result
139 metrics.iterations = result.get('iterations', 0)
140 metrics.tools_used = len(result.get('context', {}).get('actions', []))
141
142 return result
143Alerting and Anomaly Detection
Anomaly Detection System
1import time
2import logging
3import statistics
4import asyncio
5from typing import List, Callable, Dict, Any
6from collections import deque
7
8class AnomalyDetector:
9 """Simple anomaly detection for agent performance"""
10
11 def __init__(self, window_size: int = 100, threshold_std: float = 2.0):
12 self.window_size = window_size
13 self.threshold_std = threshold_std
14 self.latency_window = deque(maxlen=window_size)
15 self.success_rate_window = deque(maxlen=window_size)
16 self.alert_callbacks: List[Callable] = []
17
18 def add_alert_callback(self, callback: Callable):
19 """Add callback function for anomaly alerts"""
20 self.alert_callbacks.append(callback)
21
22 async def check_metrics(self, latency_ms: float, success: bool):
23 """Check for anomalies in real-time metrics"""
24
25 self.latency_window.append(latency_ms)
26 self.success_rate_window.append(1.0 if success else 0.0)
27
28 # Check latency anomalies (shorter window for faster spike detection)
29 if len(self.latency_window) >= 10:
30 mean_latency = statistics.mean(self.latency_window)
31 std_latency = statistics.stdev(self.latency_window)
32
33 if latency_ms > mean_latency + (self.threshold_std * std_latency):
34 await self._trigger_alert('HIGH_LATENCY', {
35 'current_latency': latency_ms,
36 'mean_latency': mean_latency,
37 'threshold': mean_latency + (self.threshold_std * std_latency)
38 })
39
40 # Check success rate anomalies (longer window for trend analysis, compare recent 10 vs overall 20)
41 if len(self.success_rate_window) >= 20:
42 recent_success_rate = statistics.mean(list(self.success_rate_window)[-10:]) # Last 10 samples
43 overall_success_rate = statistics.mean(self.success_rate_window) # Full window average
44
45 if recent_success_rate < overall_success_rate * 0.7: # 30% drop
46 await self._trigger_alert('LOW_SUCCESS_RATE', {
47 'recent_success_rate': recent_success_rate,
48 'overall_success_rate': overall_success_rate
49 })
50
51 async def _trigger_alert(self, alert_type: str, details: Dict[str, Any]):
52 """Trigger alert callbacks"""
53
54 alert_data = {
55 'type': alert_type,
56 'timestamp': time.time(),
57 'details': details
58 }
59
60 for callback in self.alert_callbacks:
61 try:
62 await callback(alert_data)
63 except Exception as e:
64 logging.error(f"Alert callback failed: {e}")
65
66# Alert handlers
67async def slack_alert_handler(alert_data: Dict[str, Any]):
68 """Send alert to Slack"""
69 # Implementation for Slack webhook
70 pass
71
72async def email_alert_handler(alert_data: Dict[str, Any]):
73 """Send alert via email"""
74 # Implementation for email notifications
75 pass
76
77async def pagerduty_alert_handler(alert_data: Dict[str, Any]):
78 """Trigger PagerDuty incident"""
79 # Implementation for PagerDuty integration
80 pass
81Key Technical Takeaways
The implementation of production-ready agentic AI systems requires careful attention to both fundamental software architecture principles and specialized prompt-orchestration patterns. As demonstrated by industry research from Anthropic, LangGraph, and leading AI engineering teams, successful agentic implementations rely on simple, composable patterns rather than complex frameworks.
Implementation Fundamentals:
- Prompt-Orchestration Patterns: Implement run-loop prompting with safe exit criteria, semantic input routing, and structured JSON response validation
- "-ilities"-Based Architecture: Prioritize usability through transparent agent interactions, maintainability via modular design, and scalability with proper resource management
- Security-First Design: Implement multi-layered guardrails, proper input validation, and audit logging for autonomous operations
- Production Reliability: Build comprehensive testing, monitoring, and validation layers to handle the non-deterministic nature of agentic systems
Architecture and Performance:
- Choose planning patterns (ReAct vs Plan-Execute) based on task complexity and latency requirements
- Implement layered memory architecture combining vector databases and knowledge graphs
- Deploy multi-layered guardrail systems with runtime policy enforcement
- Use comprehensive benchmarking with established frameworks (SWE-bench, AgentBench, τ-Bench)
- Plan infrastructure capacity based on validated Kubernetes scaling patterns.
Production Deployment Strategy:
- Use containerized deployments with Kubernetes orchestration for enterprise scale
- Implement comprehensive observability covering both traditional metrics and AI-specific performance indicators
- Deploy progressive rollout strategies with feature flags and circuit breakers
- Monitor agentic-specific metrics including autonomy levels and goal achievement rates
The rapid evolution of agentic AI capabilities makes implementation expertise a strategic advantage. Engineering teams that master these architectural patterns and prompt-orchestration techniques will be positioned to deliver transformative business value through autonomous AI systems that meet the highest standards of software architecture quality.
For organizations ready to implement agentic AI systems, the combination of proven architectural patterns, comprehensive testing strategies, and robust operational practices provides a roadmap for successful deployment at enterprise scale.
Strategic Tool Selection for CTOs
When evaluating third-party solutions, consider this decision framework:
Build vs. Buy Analysis:
- Custom Implementation: Choose when you need specific control over agent behavior, have unique requirements, or possess deep ML engineering expertise
- Managed Platforms: Opt for faster time-to-market, reduced operational overhead, and enterprise support requirements
- Hybrid Approach: Combine open-source components with managed services for cost optimization and flexibility
Vendor Selection Criteria:
- Enterprise Readiness: SOC 2 compliance, SLA guarantees, and 24/7 support availability
- Integration Ecosystem: APIs, SDKs, and compatibility with existing infrastructure tools
- Scaling Economics: Pricing models that align with usage patterns and growth projections
- Exit Strategy: Data portability, standard formats, and migration capabilities
Recommended Starting Stack for Production:
- Vector Database: Pinecone (managed) or Weaviate (self-hosted) for semantic memory
- Monitoring: Datadog or New Relic for comprehensive observability with AI extensions
- Infrastructure: Kubernetes on major cloud providers with Istio service mesh
- CI/CD: GitHub Actions or GitLab with ML pipeline extensions
- Cost Management: Spot.io or CloudHealth for automated optimization
This approach balances implementation speed with long-term architectural flexibility while providing clear ROI metrics for executive reporting.
💡 Implementation Insight: Successful agentic AI implementations follow a consistent pattern: start with managed platforms for rapid prototyping (2-4 weeks), identify performance bottlenecks and scaling constraints (4-8 weeks), then selectively replace components with custom implementations only where necessary. This hybrid approach reduces both time-to-market and total cost of ownership.
🎯 Leadership Takeaway: The companies achieving transformative results from agentic AI share three characteristics: they start with constrained use cases, invest heavily in testing infrastructure, and maintain clear metrics for autonomous decision quality.
Appendix A: Production Tool Landscape
This comprehensive vendor matrix provides CTOs and technical leaders with evaluated options for each architectural component, organized by implementation priority and enterprise readiness.
➡️ Access the Live Production Tool Landscape on GitHub: [Production Tool Landscape]
Strategic Tool Selection Framework
Build vs. Buy Decision Matrix
| Factor | Build Custom | Buy/Use Managed | Hybrid Approach |
|---|---|---|---|
| **Time to Market** | 6-12 months | 2-8 weeks | 3-6 months |
| **Total Cost (3 years)** | High upfront, low ongoing | Low upfront, high ongoing | Moderate both |
| **Control Level** | Complete | Limited | Selective |
| **Maintenance Burden** | High | Low | Medium |
| **Scaling Complexity** | High | Low | Medium |
| **Vendor Risk** | None | High | Medium |
Recommended Enterprise Starting Stack
For enterprises embarking on agentic AI, consider this pragmatic starting stack, adapting choices to your specific context:
- Vector Database: Pinecone (managed), or Weaviate (offering both managed & self-hosted options).
- Monitoring & Observability: Datadog or New Relic with AI/ML features; consider Prometheus/Grafana for OSS-centric approaches.
- Infrastructure: Kubernetes on a major cloud (AWS EKS, Azure AKS, GKE); add a service mesh (e.g., Linkerd, Istio) as complexity dictates.
- CI/CD: GitHub Actions or GitLab CI, with robust MLOps integration for AI model and agent lifecycles.
- Cost Management: Start with native cloud provider tools; leverage specialized platforms (e.g., Spot.io, CloudHealth) for advanced optimization.
Rate each vendor 1-5 on these criteria:
- Enterprise Readiness: SOC 2 compliance, SLA guarantees, 24/7 support
- Integration Ecosystem: APIs, SDKs, existing tool compatibility
- Scaling Economics: Pricing alignment with usage patterns
- Exit Strategy: Data portability, migration capabilities
- Community/Support: Documentation, community, professional services
This comprehensive tool landscape provides immediate vendor evaluation capability while supporting long-term architectural planning and procurement decisions.
References
2] [nOps. (2024). "AWS EC2 Spot Instance Pricing Guide." *nOps Blog*.
3] [Anthropic. (2024). "Building effective agents." *Anthropic Documentation*.
4] [LangChain AI. (2024). "Agentic Concepts." *LangGraph Documentation*.
6] [Amazon Web Services. (2024). "Amazon EC2 Spot Instances." *AWS Documentation*.