
Introduction: The Evaluation Bottleneck in AI Implementation
You've built an impressive AI proof-of-concept – perhaps a RAG system querying internal knowledge bases or a sophisticated document summarizer. Excitement is high, but the path to production deployment is fraught with uncertainty. How do you know it will perform reliably? How do you gain confidence before exposing it to real users? This is where many AI initiatives stumble: the evaluation bottleneck.
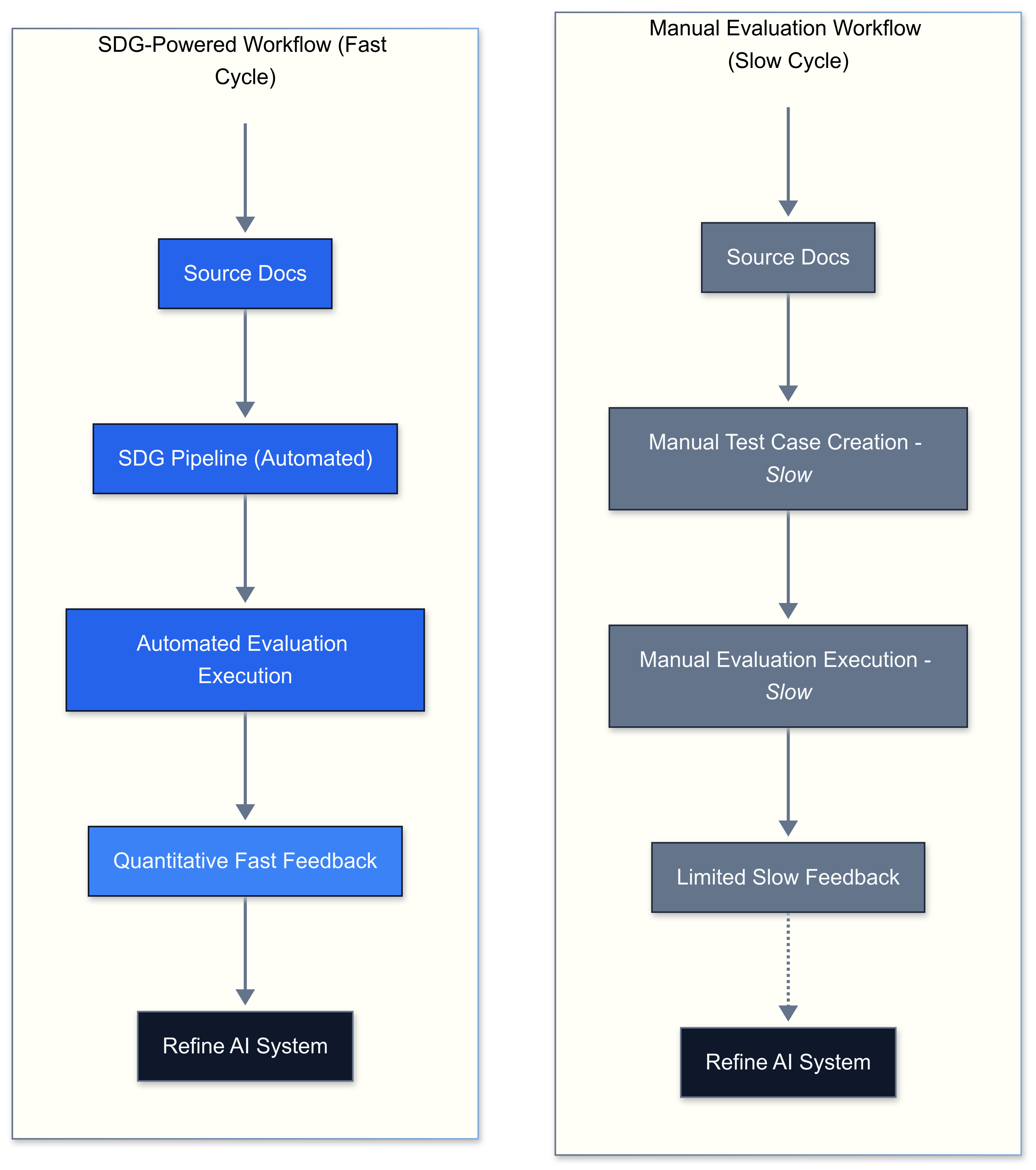
For engineering leaders, CTOs, and product managers, ensuring AI reliability, performance, and demonstrable ROI is essential. Yet, obtaining sufficient, diverse, high-quality evaluation data, especially for complex systems like RAG, is often a major hurdle. Waiting for real user interaction data delays launch and risks deploying a subpar experience. Manual test case creation is slow, expensive, and rarely covers the breadth of potential scenarios.
This is where Synthetic Data Generation (SDG) emerges as a critical enabler. SDG involves using Large Language Models (LLMs) themselves to create artificial, yet realistic, data specifically tailored for evaluating your AI systems. By generating evaluation data directly from your own documents and knowledge sources, you can rigorously test your AI before it goes live, bridging the gap between experimentation and production readiness. This post provides a practical framework and technical guidance, illustrated with three distinct SDG experiments, for robust AI evaluation, particularly focusing on RAG evaluation and LLM testing.
The Business Value: Why Invest in Synthetic Data Generation?
Implementing SDG is a technical exercise which also drives tangible business outcomes:
- Accelerated Time-to-Market: SDG overcomes the "cold start" problem. You can build robust test sets before accumulating significant user data, enabling earlier, iterative testing and faster deployment cycles.
- Reduced Costs & Increased Efficiency: Automating test data generation is significantly faster and more scalable than manual efforts. While LLM API calls for SDG incur direct costs
- potentially ranging from fractions of a cent to several cents per generated Q&A pair depending on model choice (e.g., efficient models like GPT-3.5-Turbo vs. more powerful ones like GPT-4) and complexity
- this often represents a significant order-of-magnitude reduction in both cost and time compared to the equivalent engineering or QA hours required for manual test case design, execution, and maintenance.
- Increased Confidence & Reduced Risk: Establish quantitative baselines for AI performance (e.g., retrieval accuracy, RAG faithfulness) before launch. This data-driven confidence mitigates the risk of deploying underperforming or unreliable AI systems.
- Improved AI Quality & User Experience: Synthetic data, especially evolved or context-grounded variants, helps identify knowledge gaps in source documents and weaknesses in the AI's reasoning or retrieval, guiding targeted improvements.
- Demonstrable ROI: Connecting evaluation metrics derived from SDG to system performance improvements provides a clearer path to demonstrating the value and ROI of your AI investments.
Cost Considerations for SDG Implementation
While SDG often represents a cost advantage over manual test case creation, the reality is more nuanced and depends on several factors:
Token costs vs. engineering hours: The economics vary based on your specific scenario. Creating 100 high-quality test cases might cost $10-50 in API costs using models like GPT-3.5 Turbo (cheaper) versus GPT-4 or Claude (more expensive). This must be weighed against 10-20 engineering hours to manually create comparable test cases. However, these calculations shift dramatically when extensive prompt engineering is required or when working with highly specialized domains.
Hidden costs to consider:
- Prompt engineering time (often underestimated)
- API overhead for multiple generation attempts
- Validation costs (human review remains essential)
- Infrastructure for storing and processing generated data
For organizations just starting with SDG, it's recommended to begin with a small batch and measure both direct API costs and engineering time to establish your actual cost dynamics before scaling.
Common Pitfalls: Why AI Evaluation Often Falls Short
Many organizations struggle with effective AI evaluation due to common mistakes:
- The "Evaluate Later" Fallacy: Delaying rigorous evaluation until late in the development cycle, often leading to surprises and costly rework.
- Over-reliance on Limited Real Data: Using only a small set of existing user queries or manually crafted examples, which may be biased or fail to cover edge cases and diverse scenarios.
- Manual Test Case Bottleneck: Assigning engineers or QA teams to manually write test questions and answers – a process that is inherently slow, expensive, and difficult to scale or maintain.
- Evaluating RAG Superficially: For RAG systems, simply checking if an answer sounds plausible isn't enough. Failing to verify if the answer is faithfully grounded in the retrieved context leads to undetected hallucinations.
- Using Generic Benchmarks: Relying on standard academic benchmarks that don't reflect the nuances and specific knowledge domain of your internal documents or application.
- Treating SDG Outputs as Infallible: A common mistake is over-trusting synthetic data. Its quality is inherently limited by the source documents, the chosen LLM's capabilities, and the generation prompts. SDG tools and techniques themselves are powerful but rapidly evolving; they require careful implementation and validation.
- Managing Distribution Shift in Synthetic Data: A significant limitation of SDG is the risk of distribution shift - where synthetic data exhibits patterns that differ from real-world queries. Since the same or similar foundational models may generate both your synthetic test data and power your actual RAG system, there's potential for misleading evaluation results.
- Key challenges: Synthetic data may reflect LLM biases rather than real user query patterns
- Generated questions could over-represent certain topics or question types
- Evaluation against synthetic data alone can create a false sense of system performance
- Effective mitigation strategies:
- Combine synthetic data with smaller sets of real user queries when available
- Implement measurement of diversity across generated datasets
- Ensure synthetic data generations span different parameter settings
- Use different models for data generation versus your production system
- Always incorporate human review of a sample set to identify patterns that feel artificial This hybrid approach maximizes the scalability benefits of SDG while reducing the risk of over-optimizing for synthetic patterns that don't reflect real-world usage.
- Key challenges: Synthetic data may reflect LLM biases rather than real user query patterns
A Spectrum of SDG Approaches: From Simple to Sophisticated
Effective SDG isn't one-size-fits-all. The best approach depends on your specific AI system and evaluation goals. Here's a pragmatic framework for leveraging SDG:
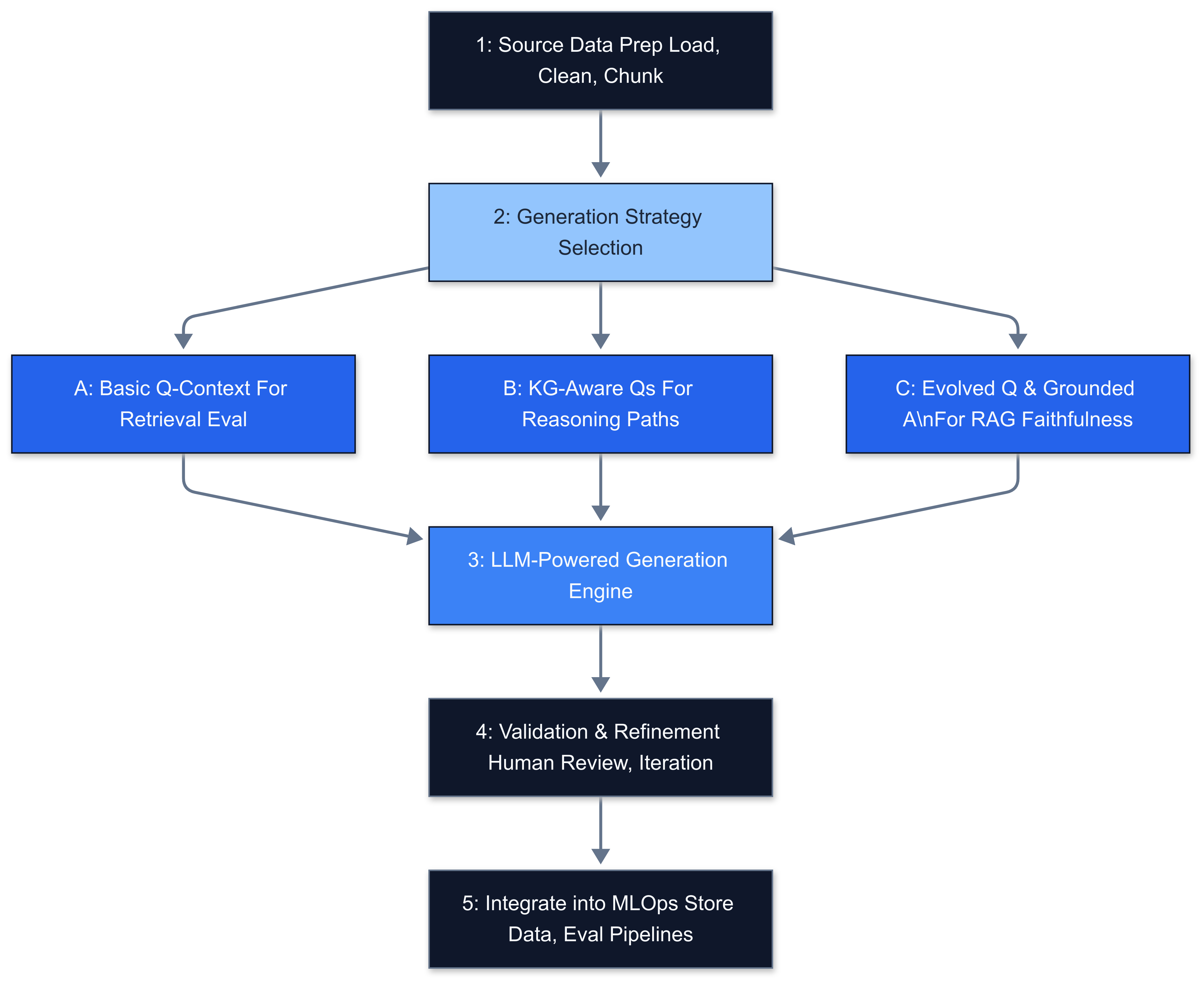
- Source Data Preparation:
(Foundation for all approaches)
- Identify & Load: Pinpoint the core documents or knowledge sources your AI needs to understand. Use appropriate loaders.
- Clean & Chunk: Preprocess text. Critically, split documents into manageable chunks. Chunking strategy impacts retrieval.
2. Generation Strategy Selection:
Choose the SDG approach matching your goals:
- (A) Basic Question-Context Pairs: Questions directly answerable by individual chunks. Goal: Test retrieval accuracy. (See Experiment 1)
- (B) KG-Aware Generation: Use tools like RAGAS to generate questions testing specific reasoning paths. Goal: Test deeper knowledge connections. (See Experiment 2)
- (C) Evolved Question & Grounded Answer Pairs: Generate diverse, complex questions and context-grounded answers. Goal: End-to-end RAG evaluation (faithfulness, relevance). (See Experiment 3)
3. LLM-Powered Generation: Implement using crafted prompts and structured output. Consider question evolution techniques for Strategy C.
4. Validation & Refinement: Crucially, review generated data quality. Remember SDG tools and LLMs are evolving; generated data isn't inherently perfect. Always include a human review step for a sample set, especially early on. Iterate on prompts and processes based on validation.
5. Integration into MLOps: Incorporate validated datasets into automated evaluation pipelines.
Integrating SDG into CI/CD
A mature implementation hooks SDG into automated workflows. For instance, a CI/CD pipeline stage could:
- Trigger the SDG pipeline (e.g., using a script invoking the LangGraph app from Experiment 3) based on documentation changes or a schedule.
- Run a validation step on the generated data (automated checks or sampling for human review).
- Version and store the validated dataset (e.g., in an artifact repository like S3/GCS).
- Execute an automated evaluation job using this dataset against the latest AI model build.
- Report key metrics (like RAG faithfulness scores) back to the build summary or monitoring dashboards.
Conceptually, a CI/CD stage might look like this (syntax illustrative):
1# Conceptual CI/CD Stage for SDG Evaluation
2- stage: Synthetic_Eval
3 trigger: # On doc change or schedule
4 script:
5 # 1. Generate Data (e.g., invoke LangGraph app)
6 - python run_sdg_pipeline.py --docs ./docs --output ./data/synthetic_eval.jsonl --limit 1000
7
8 # 2. Validate Output (custom script/tool)
9 - python validate_sdg.py --input ./data/synthetic_eval.jsonl
10
11 # 3. Version & Store Dataset (using CI/CD artifact features)
12 - upload_artifact name=eval_dataset path=./data/synthetic_eval.jsonl version=$CI_COMMIT_SHA
13
14 # 4. Run Evaluation (using RAGAS, custom scripts, etc.)
15 - python run_rag_eval.py --dataset eval_dataset:$CI_COMMIT_SHA --model $MODEL_ENDPOINT --report ./results/eval_report.json
16
17 # 5. Report Metrics
18 - publish_metric name=rag_faithfulness value=$(cat ./results/eval_report.json | jq .faithfulness)
19 - publish_metric name=answer_relevance value=$(cat ./results/eval_report.json | jq .answer_relevance)
20Note: The specific implementation depends heavily on your CI/CD platform (GitHub Actions, GitLab CI, Jenkins, etc.) and chosen evaluation tools.
Illustrative Examples: SDG Techniques in Action
Let's look at three concrete experiments demonstrating these approaches, using LangChain documentation as our source material.
Experiment 1: Basic Question-Context Generation
- Goal: Quickly bootstrap evaluation, especially for retrieval accuracy.
- Method: LLM + `instructor` for structured output from single chunks. (Ref: `SDG_basic_skill.ipynb`)
- Key Code Concept (Conceptual Prompting with `instructor`):
1 # Conceptual: Using instructor to get structured Question output
2 # ... (imports and class definition as before) ...
3 response = client.chat.completions.create(
4 model="gpt-4o-mini", # Or your preferred model
5 response_model=Question,
6 messages=[
7 {"role": "system", "content": "Generate a question answerable *only* from the provided context."},
8 {"role": "user", "content": f"Context: {document_chunk_text}\n---\nGenerate question:"}
9 ]
10 )
11- Sample Output Table:
| **Chunk ID** | **Source URL** | **Generated Question** | **Source Chunk (Snippet)** |
|---|---|---|---|
| lc_doc_chunk_123 | `https://.../docs/concepts/#retrieval...` | According to the documentation, what is the primary purpose of a Retriever in LangChain? | ... a Retriever is an interface that returns documents given an unstructured query... |
| lc_doc_chunk_45 | `https://.../docs/tutorials/rag/` | How can document loaders be used to ingest data from different sources for a RAG system? | ... Document loaders provide a way to load data from various sources like PDFs... |
| lc_doc_chunk_89 | `https://.../docs/concepts/#agents` | What role does the AgentExecutor play in managing agent interactions? | ... The core idea of agents is to use an LLM to choose a sequence of actions... AgentExecutor... |
- Value: Excellent for quickly testing retrieval accuracy.
Experiment 2: KG-Aware Generation with Ragas
- Goal: Test deeper understanding and reasoning over the knowledge base.
- Method: Use Ragas `TestsetGenerator` with its internal Knowledge Graph capabilities and specialized synthesizers. (Ref: `SDG_RAGAS.ipynb`)
- Key Code Concept (Ragas Synthesizer Distribution):
1 # Conceptual: Defining the mix of question types in Ragas
2 # ... (imports as before) ...
3 query_distribution = [
4 (SingleHopSpecificQuerySynthesizer(llm=your_ragas_llm_wrapper), 0.7),
5 (MultiHopAbstractQuerySynthesizer(llm=your_ragas_llm_wrapper), 0.3)
6 ]
7 # Pass to generator.generate(...)
8- Sample Output Table:
| **user_input (Question)** | **reference_contexts (Snippets used)** | **reference (Generated Answer)** | **synthesizer_name** |
|---|---|---|---|
| How does LangChain Expression Language (LCEL) facilitate chain composition? | `[LangChain Expression Language (LCEL)... provides a declarative way...]` | LCEL allows declarative chaining of LangChain components using a pipe protocol... | single_hop_specifc_query_synthesizer |
| What is the relationship between document splitting strategies and retrieval effectiveness? | `[<1-hop>\n\nSplitting documents... impacts retrieval quality... ]` | Document splitting breaks down large documents... impacting retrieval quality... | multi_hop_abstract_query_synthesizer |
| How can LangSmith debug RAG involving vector stores? | `[<1-hop>\n\nLangSmith helps debug... <1-hop>\n\nVector stores...]` | LangSmith provides tracing... helping debug RAG pipelines that utilize vector stores... | multi_hop_specific_query_synthesizer |
- Value: Creates targeted questions to evaluate connection-making capabilities.
Experiment 3: Evolved Q&A for RAG Evaluation
- Goal: Generate robust data for end-to-end RAG evaluation (faithfulness, relevance).
- Method: Use LangGraph to orchestrate: seed question -> evolve question -> retrieve context -> generate context-grounded answer. (Ref: `Synthetic_Data_Generation_Eval.ipynb`)
- Key Code Concept (Grounded Answer Generation Prompt):
1 # Conceptual Prompt for the Grounded Answer Generation Node
2 # ... (imports and class definition as before) ...
3 prompt = ChatPromptTemplate.from_messages([
4 ("system", "You are an expert at answering questions based STRICTLY and ONLY on the provided CONTEXT... If the context does not contain the answer, state that clearly..."),
5 ("human", "CONTEXT:\n{context}\n\n---\n\nQUESTION:\n{question}\n\n---\n\nANSWER (Based ONLY on the context above):")
6 ])
7 # Use with llm.with_structured_output(GroundTruthAnswer)
8- Sample Output Table:
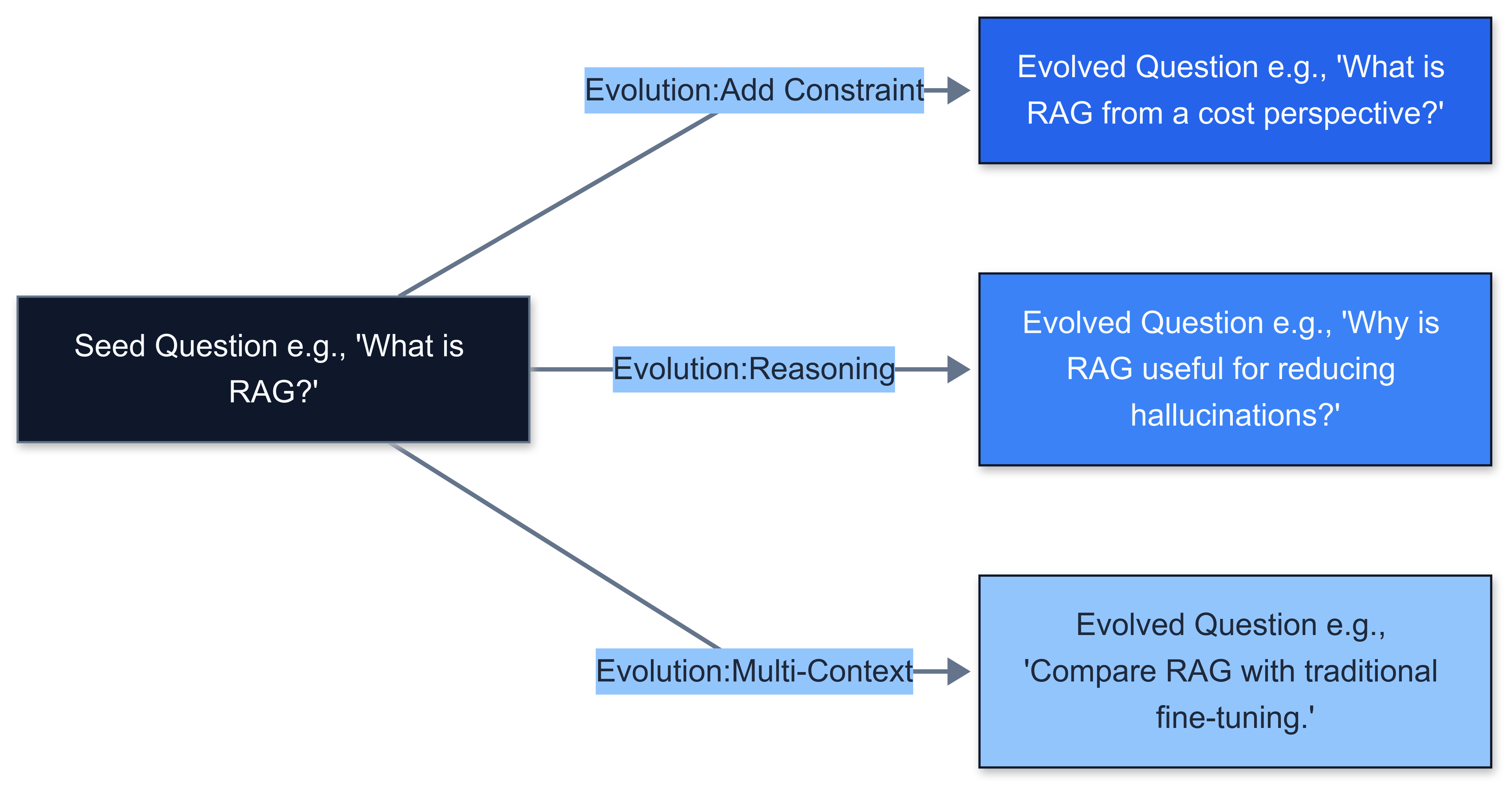
| **Seed Question** | **Evolution Type** | **Evolved Question** | **Generated Answer (Context-Based)** |
|---|---|---|---|
| What is Retrieval Augmented Generation (RAG)? | Reasoning | Why is RAG considered powerful for enhancing LLM responses? | RAG is powerful because it grounds the LLM on external knowledge sources, reducing hallucinations and allowing answers based on specific, up-to-date information in the retrieved context... |
| How are agents used in LangChain? | Add Constraints | How are agents used in LangChain specifically for tasks involving external API calls? | Agents in LangChain can use tools, including API wrappers. The AgentExecutor manages the agent's decision to call a specific tool (API) based on input and reasoning... |
| What is the role of vector stores? | Multi-Context | Compare vector stores' role in simple retrieval vs. complex agentic workflows. | In simple retrieval, vector stores enable semantic search. In agentic workflows, the agent decides *when* and *how* to use them as part of a larger plan... |
- Value: Produces high-fidelity test cases essential for evaluating RAG faithfulness.
Implementation Considerations (Team Size & Scale)
- Small Teams / Startups: Start with Experiment 1 (Basic Q-Context). Focus on core docs. Manual validation is crucial. Be mindful that SDG tools are evolving; test library upgrades.
- Medium / Large Organizations: Implement Experiment 3 (Evolved Q&A) for robust RAG testing. Use LangGraph for orchestration. Integrate into MLOps (see CI/CD section). Explore Experiment 2 (Ragas KG) for specific needs. Monitor LLM costs (GPT-3.5 vs. GPT-4). Factor in time for prompt engineering and validation cycles.
- Tooling: LangChain, LangGraph, Ragas, Instructor, Vector DBs (FAISS, Chroma, Pinecone), Eval Frameworks (RAGAS, TruLens).
Measuring Success: Metrics for SDG and Evaluation
How do you know your Synthetic Data Generation effort is effective?
Metrics for the SDG Process:
- Generation Rate & Cost per Pair
- Source Document Coverage (%)
- Quality Score (Human Review on sample)
- Diversity Score (Advanced, e.g., embedding distance)
Metrics for AI System Evaluation (Using SDG Data):
- Retrieval: Context Recall / Hit Rate (Using Exp 1 data)
- RAG: Faithfulness, Answer Relevance, Context Relevance (Using Exp 3 data via frameworks like RAGAS)
Unique Insight & Future Trends
The true power of advanced SDG (like Experiment 3) lies in generating challenging data that probes specific failure modes. The focus on context-grounded answer generation is paramount for building trust in RAG systems by directly tackling hallucination tendencies. It moves evaluation beyond surface-level fluency to factual consistency based only on the provided evidence.
Looking ahead, expect SDG techniques to become crucial for evaluating more complex agentic systems. Generating synthetic dialogues, sequences of tool use, and multi-step reasoning scenarios will be essential for ensuring these increasingly autonomous systems behave reliably and safely. Mastering SDG now builds foundational capability for this future.
Conclusion: From Guesswork to Grounded Confidence
Moving AI from promising prototypes to reliable production systems demands rigorous evaluation. Synthetic Data Generation offers a powerful, practical solution to the common bottleneck of insufficient or inadequate test data. By leveraging LLMs to generate tailored evaluation datasets grounded in your own data – from basic retrieval tests (Experiment 1) to reasoning probes (Experiment 2) and complex RAG faithfulness checks (Experiment 3) – you can:
- Gain early confidence in your AI's performance.
- Identify weaknesses in your knowledge base and AI reasoning.
- Accelerate your development and deployment cycles.
- Build more reliable, trustworthy AI solutions.
Actionable Next Steps:
- Identify: Pinpoint the core knowledge source for your AI system.
- Start Simple: Implement a basic Q-Context generation pipeline (like Experiment 1).
- Integrate: Feed this data into your testing process or an evaluation framework.
- Evolve: For RAG, progress to generating evolved questions and context-grounded answers (like Experiment 3).
- Iterate: Continuously refine your SDG process and your AI system based on evaluation results.
This is the first in a three-part series exploring AI evaluation strategies — subscribe to our newsletter to receive the upcoming articles on metric design and production monitoring frameworks directly in your inbox.
------
Struggling to implement these evaluation strategies or optimize your RAG system's performance? Building effective SDG pipelines and integrating them into robust evaluation frameworks requires specialized expertise. As an AI Engineering Consultant, I partner with engineering leaders, CTOs, and product managers to navigate these complexities, implement best practices in Synthetic Data Generation and AI Evaluation, and build AI systems that deliver measurable business value with confidence.
Ready to replace guesswork with grounded insights? Let's discuss how tailored SDG and evaluation strategies can de-risk and accelerate your AI roadmap.