
Abstract
This blog evaluates visual grounding models on professional accounting software interfaces. Testing GroundNext-7B and ShowUI-2B across 595 grounding targets from four platforms (Odoo, QuickBooks Online, ERPNext, Dolibarr ), the results show a significant performance gap compared to published benchmark results.
GroundNext-7B achieves 13.28% accuracy on accounting UI compared to 50.2% on ScreenSpot-Pro—a 37 percentage point gap. ShowUI-2B achieves 0.15% accuracy on this benchmark. The 89-94% SOTA agreement rate indicates both models produce incorrect predictions on similar samples, suggesting ensemble strategies may have limited benefit.
Semantic aliasing (42.8%) emerges as the dominant failure mode, followed by icon scale (33.7%) and coordinate regression (23.4%). Platform variance is high: Odoo's modern OWL framework achieves 45.98% while ERPNext achieves only 3.70%, suggesting UI complexity significantly impacts grounding performance.
These findings suggest domain-specific fine-tuning may be beneficial for deploying visual grounding models in vertical enterprise applications.
1. Introduction
Visual grounding is the task of localizing UI elements from natural language descriptions, is foundational to Computer-Use Agents (CUAs). Recent models report impressive benchmark performance: ShowUI-2B achieves 7.7% on ScreenSpot-Pro, while GroundNext-7B (trained on 700K instruction pairs from the GroundCUA dataset) achieves 50.2% on the same benchmark [1].
This study validates this assumption on accounting software.
The evaluation covers SOTA grounding models on professional accounting software, a vertical enterprise domain characterized by dense information displays, small interactive elements, and repetitive form structures. The results show models achieving 50-75% on standard benchmarks achieve 0-13% on accounting interfaces.
1.1 Contributions
- Accounting-specific grounding benchmark spanning 4 platforms, 65 screenshots, and 595 validated targets
- Quantified domain gap of 37 percentage points(GroundNext-7B) between published and real-world accuracy
- Failure taxonomy identifying semantic aliasing, icon scale, and coordinate regression as primary failure modes
- Platform variance analysis revealing 42pp accuracy range (3.7%-46%) correlated with UI framework modernity
2. Related Work
2.1 Visual Grounding Models
GroundNext-7B [1] extends Qwen2.5-VL-7B with training on the GroundCUA dataset (700K instruction pairs from 56K desktop screenshots). It achieves 50.2% (SFT) / 52.9% (RL) on ScreenSpot-Pro.
ShowUI-2B [2] introduces UI-guided token selection for efficient grounding, achieving 7.7% on ScreenSpot-Pro with only 2B parameters (75.1% on original ScreenSpot)
UGround-V1-7B [3] trains on 10M UI elements from 1.3M screenshots, achieving 31.1% on ScreenSpot-Pro.
2.2 GUI Benchmarks
- ScreenSpot [4]: Web and mobile interfaces
- ScreenSpot-Pro [5]: Professional software subset
- Mind2Web [6]: Web navigation tasks
Existing benchmarks primarily evaluate consumer applications:
No benchmark specifically targets enterprise ERP/accounting software, despite its prevalence in business automation use cases.
3. Benchmark: accounting_grounding_v1
3.1 Platform Coverage
| Platform | Framework | Screenshots | Targets | Description |
|---|---|---|---|---|
| Odoo | OWL | 24 | 87* | Open-source ERP |
| QuickBooks Online | React | 18 | 193 | Commercial SaaS |
| ERPNext | Frappe | 10 | 81 | Open-source ERP |
| Dolibarr | PHP | 13 | 234 | Open-source ERP |
| **Total** | - | **65** | **595** | - |
*77 Odoo samples excluded due to data quality issues (see Section 3.4)
3.2 Target Characteristics
- Navigation (sidebar, menus, tabs)
- List Navigation (table rows, pagination, filters)
- Data Entry (form fields, inputs, dropdowns)
- Authentication (login flows)
Task Categories:
- Small: <0.1% viewport (toolbar icons, action buttons)
- Medium: 0.1-1% viewport (form fields, menu items)
- Large: >1% viewport (main content areas)
Element Sizes:
- Easy: Large, clearly labeled elements
- Medium: Standard elements with common labels
- Hard: Small icons, ambiguous labels, dense regions
Difficulty Levels:
3.3 Annotation Format
- Pixel-precise bounding box coordinates
- Multiple instruction variants (generic, specific, verbose)
- Element metadata (type, size, area ratio)
- Ground truth center coordinates
- Difficulty classification
Each target includes:
3.4 Data Quality
77 Odoo samples from `form_01`, `nav_01`, and `vendor_01` directories were excluded due to missing screenshots during evaluation. This affected Odoo's sample count (87 valid of 164 total) but did not impact QBO, ERPNext, or Dolibarr data.
4. Experimental Setup
4.1 Models Evaluated
GroundNext-7B (ServiceNow/GroundNext-7B-V0)
- Architecture: Qwen2.5-VL-7B (8B parameters)
- Output: Pixel coordinates via tool call JSON format
- Published: 50.2% ScreenSpot-Pro (SFT)
ShowUI-2B (showlab/ShowUI-2B)
- Architecture: Qwen2-VL-2B with UI-guided token selection
- Output: Normalized coordinates [0, 1]
- Published: 7.7% ScreenSpot-Pro
4.2 Evaluation Protocol
Metric: Point-in-box accuracy prediction is correct if (x, y) falls within ground truth bounding box.
Infrastructure: Modal Labs serverless GPU (NVIDIA A10G, 24GB VRAM)
- GroundNext-7B: ~19s per sample (~4 hours total)
- ShowUI-2B: ~2.2s per sample (~25 min total)
Inference Time:
4.3 Batch Processing
- Batch size: 200 samples
- Checkpoint saves after each batch
- Resume capability on timeout
- Total runtime: ~4.5 hours
Due to inference latency, batch processing was implemented:
5. Results
5.1 Overall Accuracy
| Model | Accuracy | Samples | Mean Latency |
|---|---|---|---|
| GroundNext-7B | **13.28%** | 595 | 19,060ms |
| ShowUI-2B | **0.15%** | 684 | 2,200ms |
5.2 Domain Gap Quantification
| Model | ScreenSpot-Pro | Accounting UI | Gap |
|---|---|---|---|
| GroundNext-7B | 50.2% | **13.28%** | **-36.9pp** |
| ShowUI-2B | 7.7% | 0.15% | -7.55pp |
This suggests models trained on general UI do not transfer well to accounting interfaces without additional fine-tuning.
5.3 Cross-Platform Performance
| Platform | Accuracy | Samples | Successes | Framework |
|---|---|---|---|---|
| Odoo | **45.98%** | 87 | 40 | OWL (Modern) |
| QBO | 9.84% | 193 | 19 | React |
| ERPNext | 3.70% | 81 | 3 | Frappe |
| Dolibarr | 7.26% | 234 | 17 | PHP (Legacy) |
Key Finding: Platform variance spans 42.3 percentage points. Odoo's modern OWL framework achieves 12x higher accuracy than ERPNext, suggesting UI framework modernity significantly impacts grounding performance.
5.4 SOTA Agreement Analysis
| Agreement Type | Percentage |
|---|---|
| Both Fail | 89-94% |
| Both Succeed | 0-6% |
| GroundNext Only | 6-11% |
| ShowUI Only | 0% |
The 89-94% agreement rate indicates models produce incorrect predictions on similar samples. This suggests ensemble strategies may have limited benefit when failure modes overlap.
5.5 Performance by Element Size
| Size | Area Ratio | GroundNext-7B | ShowUI-2B |
|---|---|---|---|
| Large | >1% | **23.08%** | 0% |
| Medium | 0.1-1% | 9.68% | 0% |
| Small | <0.1% | 8.93% | 0% |
Even large elements achieve only 23% accuracy—far below the 50%+ expected from benchmark performance.
5.6 Performance by Task Category
| Category | GroundNext-7B | ShowUI-2B |
|---|---|---|
| Navigation | **23.08%** | 0% |
| List Navigation | 0% | 0% |
| Data Entry | 0% | 0% |
List navigation and data entry—core accounting workflows—show 0% accuracy across both models.
6. Failure Analysis
6.0 Visual Examples of Failure Cases
The following figures show example predictions on accounting UI. Green circles indicate ground truth locations; red X marks indicate model predictions.
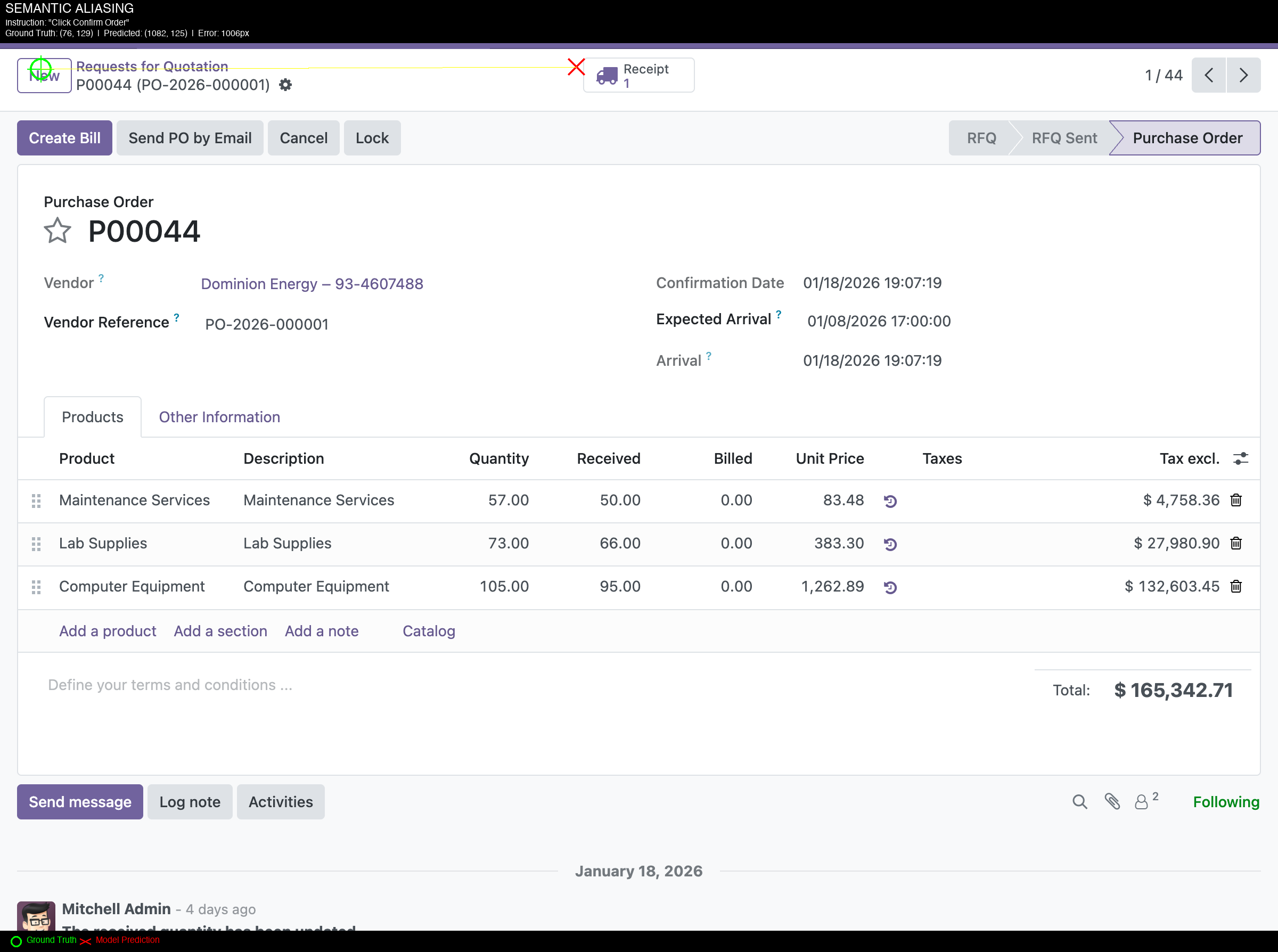
Figure 1: Semantic Aliasing - "Click Confirm Order" (1006px error) Model predicted (1082, 125) instead of ground truth (76, 129). The prediction landed on "Purchase Order" button on the right instead of the target action button on the left.
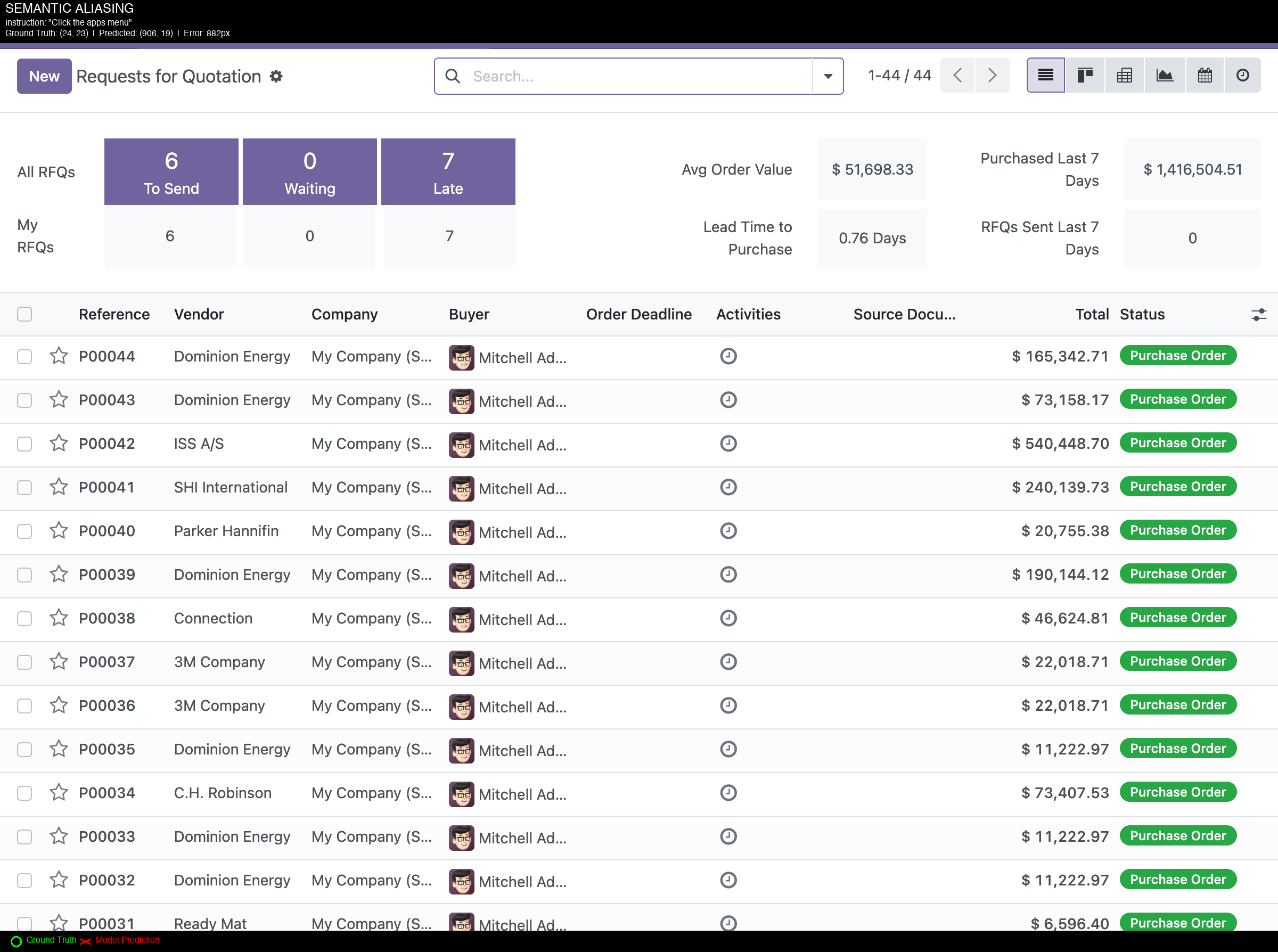
Figure 2: Semantic Aliasing - "Click the apps menu" (882px error) Model predicted (906, 19) instead of ground truth (24, 23). The target was a small grid/apps icon (17x17px) in the top-left corner.
These examples illustrate the gap between benchmark performance and performance on enterprise software.
6.1 Failure Taxonomy
| Failure Type | Count | Percentage | Description |
|---|---|---|---|
| **Semantic Aliasing** | 221 | **42.8%** | Confusion between similar labels |
| Icon Scale | 174 | 33.7% | Small elements not detected |
| Coordinate Regression | 121 | 23.4% | Correct element, imprecise coordinates |
6.2 Platform-Specific Failure Patterns
| Platform | Semantic Aliasing | Icon Scale | Coord. Regression |
|---|---|---|---|
| Odoo | 70.2% | 2.1% | 27.7% |
| QBO | 58.6% | 25.3% | 16.1% |
| ERPNext | 46.2% | 9.0% | 44.9% |
| Dolibarr | 23.0% | **56.2%** | 20.7% |
Dolibarr's legacy PHP interface shows icon scale dominance (56.2%), while QBO's React interface shows semantic aliasing dominance (58.6%).
6.3 Semantic Aliasing Examples
| Instruction | Prediction | Ground Truth | Error Type |
|---|---|---|---|
| "Click Account num header" | Parent account header | Account num header | Wrong column |
| "Click Save button" | Submit button | Save button | Similar label |
| "Click account 101" | Account 100 row | Account 101 row | Adjacent row |
Accounting forms contain repetitive, visually similar elements that may be challenging for models trained primarily on consumer UI.
6.4 Icon Scale Analysis
| Element Type | Typical Size | Viewport % | Performance |
|---|---|---|---|
| Menu bar icons | 35x35px | 0.06% | Low |
| Toolbar buttons | 25x25px | 0.03% | Low |
| Action icons | 20x20px | 0.02% | Low |
| Grid/hamburger | 17x17px | 0.01% | Low |
Accounting UI elements are 10-80x smaller than mobile/web design standards (iOS: 44x44pt minimum, Material: 36x36dp minimum).
7. Discussion
7.1 Why the Domain Gap Exists
- ScreenSpot-Pro: Modern web apps, mobile interfaces, clean visual hierarchy
- Accounting UI: Dense ERP interfaces, tiny toolbar icons, repetitive form fields
Training Distribution Mismatch:
Element Density: A typical accounting form contains 20+ interactive elements in a 1920x1080 viewport, many sharing identical visual styling. This density may exceed what current training datasets represent.
Domain Vocabulary: Instructions like "Click the Due Date field" use accounting terminology that may be underrepresented in general GUI training data. Disambiguating among multiple date-related fields on an invoice form may require domain-specific training.
7.2 Ensemble Considerations
High SOTA agreement (89-94%) suggests ensemble approaches may have limited benefit. Both models fail on similar samples because:
- Shared training distributions lack ERP exposure
- Icon scale failures affect all VLM-based grounders equally
- Semantic aliasing requires domain-specific disambiguation training
7.3 Platform Variance Implications
The 42pp accuracy range across platforms suggests:
- Modern UI frameworks (OWL, React) provide cleaner grounding signals
- Legacy interfaces (PHP) with inconsistent styling are harder to ground
- Fine-tuning should prioritize lowest-performing platforms (ERPNext, Dolibarr)
8. Recommendations
8.1 For CUA Practitioners
- Validate on target domain before vertical deployment. ScreenSpot-Pro performance may not predict accounting UI performance.
- Evaluate on target domain before deployment. Run real GPU inference on your specific application.
- Expect 37pp degradation when moving from consumer to enterprise applications.
- Consider domain-specific fine-tuning for accounting automation use cases.
8.2 For Fine-Tuning Strategy
| Failure Mode | % | Training Data Focus |
|---|---|---|
| Semantic Aliasing | 42.8% | Similar labels, form field disambiguation |
| Icon Scale | 33.7% | Small icons, toolbar buttons, dense menus |
| Coordinate Regression | 23.4% | Near-miss cases, bounding box precision |
Collect 500+ training pairs balanced across platforms and failure modes. Prioritize hard examples from ERPNext (3.7%) and Dolibarr (7.3%).
9. Limitations & Discussion
9.1 ShowUI's Low Accuracy
ShowUI-2B achieved 0.15% (1/684 correct predictions). Potential evaluation bugs were investigated:
- Output format verified: ShowUI outputs normalized [0,1] coordinates. Correct denormalization to pixel space was confirmed.
- Inference validated: Manual inspection of predictions showed the model produces valid coordinate outputs, but they consistently land on incorrect elements.
- Possible explanation: ShowUI was trained primarily on web/mobile UI. Accounting software's dense, small-element layouts may fall outside its effective training distribution. Others are welcome to reproduce and verify.
9.2 Sample Size
- The consistency of results across 4 independent platforms suggests the pattern is real
- The 37pp gap is large enough that sampling variance is unlikely to explain it
- The full dataset is released for others to extend
595 valid targets across 65 screenshots is modest. Larger benchmarks would strengthen conclusions. However:
9.3 Odoo Data Quality
- Odoo's higher accuracy is consistent with its modern OWL framework
- The excluded samples were random (infrastructure failure, not selection bias)
- Other platforms (QBO, ERPNext, Dolibarr) were unaffected
77 Odoo samples were excluded due to missing screenshots during Modal evaluation (file sync issue). This reduced Odoo from 164 to 87 samples. The 45.98% accuracy is based on valid samples only. Key points:
9.4 Distribution Shift vs. Benchmark Overfitting
One interpretation: models are overfit to ScreenSpot's distribution, not that accounting UI is "harder." This is better framed as distribution shift the training data for these models underrepresents enterprise software. This is expected given training datasets are scraped from consumer web/mobile apps. The finding is still actionable: if deploying to enterprise, evaluate on enterprise data.
9.5 Reproducibility
- Dataset: huggingface.co/datasets/s4um1l/accounting_grounding_v1
- Evaluation: Modal A10G GPU, standard inference
- Metric: Point-in-box accuracy (prediction inside ground truth bounding box)
10. Conclusion
This study evaluated visual grounding models on professional accounting software. The results show a performance gap: GroundNext-7B drops from 50.2% (ScreenSpot-Pro) to 13.28% (accounting UI), while ShowUI-2B drops from 7.7% to 0.15%.
Summary of Findings:
| Metric | Value |
|---|---|
| Best Model Accuracy | 13.28% (GroundNext-7B) |
| Worst Model Accuracy | 0.15% (ShowUI-2B) |
| Domain Gap | 37-75pp |
| SOTA Agreement | 89-94% |
| Primary Failure Mode | Semantic Aliasing (42.8%) |
| Platform Range | 3.70% - 45.98% |
Current benchmarks primarily cover consumer applications.
Key Insight: The 42pp platform variance (Odoo 46% vs ERPNext 3.7%) suggests UI framework modernity significantly impacts grounding performance, providing a roadmap for prioritizing fine-tuning data collection.
Takeaway: Domain-specific evaluation and fine-tuning may be necessary for vertical enterprise applications. Benchmark performance on consumer applications may not generalize to enterprise software.
References
[1] ServiceNow Research. "GroundCUA: Grounded GUI Agents via Reinforcement Learning." arXiv:2511.07332, 2025.
[2] ShowLab. "ShowUI: One Vision-Language-Action Model for GUI Visual Agent." arXiv:2411.17465, 2024.
[3] OSU NLP. "UGround: Universal Visual Grounding for GUI Agents." ICLR 2025 Oral.
[4] Cheng et al. "ScreenSpot: A Large-scale Benchmark for Visual Grounding." 2024.
[5] Li et al. "ScreenSpot-Pro: Professional Software Benchmark for Visual Grounding." 2024.
[6] Deng et al. "Mind2Web: Towards a Generalist Agent for the Web." NeurIPS 2023.
Appendix A: Benchmark Statistics
| Metric | Value |
|---|---|
| Total Screenshots | 65 |
| Total Targets | 684 |
| Valid Targets | 595 |
| Platforms | 4 |
| Task Categories | 6 |
| Resolution | 1920x1080 |
| Evaluation Infrastructure | Modal A10G GPU |
| Total Compute Time | ~5 hours |
Appendix B: Reproducibility
Benchmark Dataset: huggingface.co/datasets/s4um1l/accounting_grounding_v1
1accounting_grounding_v1/
2 odoo/ # 24 screenshots
3 qbo/ # 18 screenshots
4 erpnext/ # 10 screenshots
5 dolibarr/ # 13 screenshots
6---
Benchmark version: accounting_grounding_v1 Models: GroundNext-7B (ServiceNow), ShowUI-2B (ShowLab) Infrastructure: Modal Labs A10G GPU Total samples: 595 valid / 684 total