
Introduction
I'm building a computer-use agent against real enterprise UIs. Not an API wrapper something that has to perceive interfaces, identify real elements, and act in a way a human can inspect and understand.
Milestone 1 was about perception infrastructure. The goal was narrow: get an agent to reliably see a stateful enterprise application well enough to act on it without guessing.
I chose accounting software (mostly Odoo, with other enterprise interfaces as reference) because it exposes failure modes early: deeply nested iframes, DOMs that re-render on every interaction, custom widget systems, and workflows where a wrong click has consequences. If perception holds up here, it usually holds elsewhere.
This is a dev log of what I learned.
Containerization from Day One
I containerized everything in the first week not because I needed cloud deployment yet, but because containers surface problems local development hides.
The setup was straightforward: a Docker container running Playwright + Chromium, Xvfb for a virtual display, VNC for visual debugging, PostgreSQL for session persistence, and a FastAPI server for the streaming UI.
The first issue showed up immediately. Browser rendering inside a headless Linux container behaves differently than on macOS. Things that “worked” locally failed silently in the container.
The earliest reliable signal turned out to be screenshot size. When screenshots dropped below a certain threshold, the page usually hadn’t rendered at all—even though no error was raised.
That became the first invariant: confirm rendering before debugging anything else.
Process Isolation Is a Real Architecture Constraint
This problem doesn’t show up in local development.
The system has a streaming UI that shows live screenshots and agent state over WebSockets. Locally, everything ran in a single process. The automation code and the server shared memory. Broadcasting updates just worked.
In Docker, I ran the automation via `docker exec`, which meant it lived in a separate process. The automation process had its own `ConnectionManager`. The server had a different one. WebSocket clients connected to the server, not the automation process.
The symptoms were confusing at first:
- screenshots never appeared
- reasoning updates were silent
- remote control commands went nowhere
Nothing was wrong with the code. The assumption about process boundaries was wrong.
The fix required making communication explicit:
- Automation pushes observations to the server over HTTP
- Automation polls the server for commands
- Only the server owns WebSocket connections
This adds latency and isn’t how I’d design it long-term. A message queue would be cleaner. But for Week 1, this unblocked development without adding infrastructure I didn’t yet need.
The takeaway is simple: if the system will run in containers later, it needs to run in containers now. Process-boundary bugs only appear when boundaries exist.
Session Persistence and Why It Matters
Enterprise software requires authentication. Re-logging in on every run slows iteration and makes debugging miserable.
I added session persistence: after login, cookies and localStorage are saved to PostgreSQL and restored on the next run.
This worked until sessions expired. A restored session could load the UI but fail silently on backend calls.
The fix was explicit session validation. On restore, the agent hits a known endpoint and checks the response. If validation fails, the session is discarded immediately and the error is surfaced.
This validation is shallow—it only confirms the session is alive, not that it has the right permissions everywhere. That’s fine for now. Silent failure was the bigger problem.
Stale state wastes more time than no state at all.
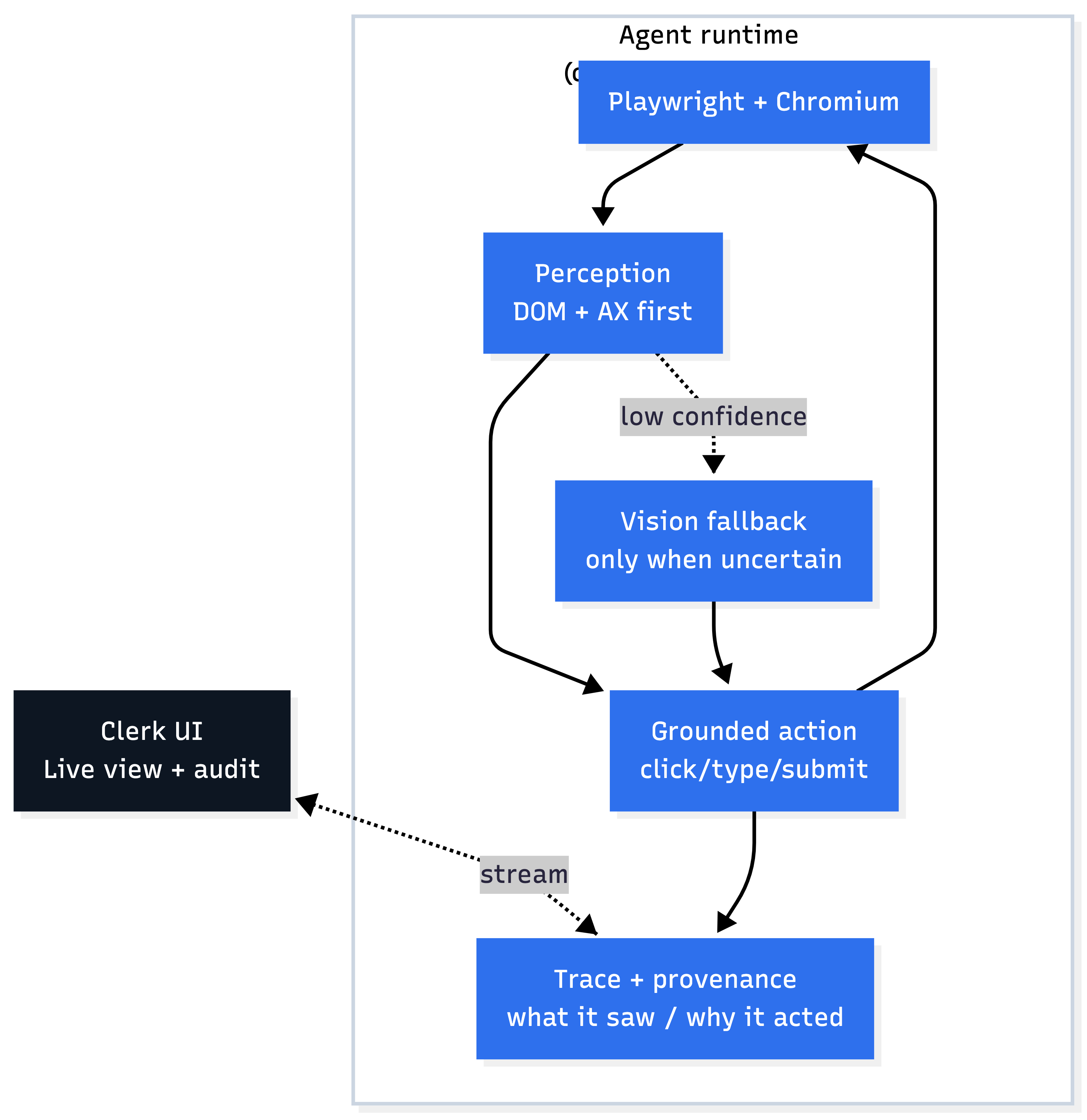
Why Purely Structural Perception Breaks Down
I started with DOM-based perception: selectors, attributes, event hooks. It works until the UI changes. Selectors describe where something is, not what it represents.
The accessibility tree is more semantic. Roles, names, and relationships are closer to how humans think about interfaces. Since Playwright deprecated their AX API, I dropped down to the Chrome DevTools Protocol and pulled the full accessibility tree directly.
Even with DOM + AX, some elements are effectively invisible.
A concrete example: Odoo’s toolbar buttons. Multiple buttons rendered as generic `<div>`s with minimal attributes. The AX tree exposes little useful distinction. Structurally, they look identical.
A human distinguishes them instantly by iconography.
That’s where vision comes in. I added a vision-language model that inspects screenshots and identifies elements visually.
Vision helps, but it’s slow and unreliable. Calls take seconds and sometimes return confident answers to things that aren’t there.
So the system defaults to structure. DOM and AX tree run first. Only when confidence is low does vision get involved. Vision acts as a fallback, not the primary signal.
Every detected element carries provenance: which method identified it and with what confidence. That data is already useful for debugging, and it will become training signal later.
Invoice Ingestion Before Navigation
Before the agent can act, it needs to understand what it’s acting on.
I built a multi-modal invoice extraction pipeline:
- structured PDF parsing for tables, headers, and line items
- vision fallback when structure extraction fails
The main issue wasn’t extraction accuracy—it was output consistency. Vision outputs varied widely in format. Without validation, malformed extractions flowed downstream and broke everything later.
I added schema validation at the extraction boundary. Anything that doesn’t match the expected structure is rejected immediately.
External inputs are untrusted. Internal state shouldn’t be.
Failure Data Is Easy to Lose
The longer-term plan is preference learning. That requires both successful actions and failures.
Successes were easy to log. Failures weren’t.
When an action failed—timeout, missing element, wrong click—an exception was thrown and the episode terminated. No data was recorded. I was discarding the most valuable data by default.
The fix was to make failure a first-class path. Observations are captured before actions. If the action fails, the failure is recorded with the observation intact. Only then does the exception propagate.
Most automation frameworks are designed to stop on failure. That’s reasonable for scripting. It’s actively harmful for data collection.
Week 1 Metrics (Expanded Runs)
Initial smoke tests were small. I let the pipeline run longer to confirm stability and data characteristics.
Across expanded runs on Odoo and a smaller set on QBO:
- DOM–vision agreement stabilized in the low 90s
- negative example ratios stayed within the target range for preference learning
- recovery paths were exercised regularly, especially in re-render-heavy flows
This is still early. The goal here isn’t performance—it’s verifying that the system produces usable training data without silent failure.
Scale comes later.
The Trust Constraint
I keep coming back to the same constraint: if a human can’t see why the agent clicked something, they won’t trust it.
The system streams what the agent sees, which elements it detected, which signals mattered, and what it plans to do next. This started as a debugging tool. It’s clearly part of the product surface.
Opacity is tolerable in demos. It breaks down quickly in business software.
Open Questions
- Do policies trained on Odoo transfer cleanly to other products, or is perception itself product-specific?
- When structure and vision disagree, what should the agent do in real time?
- How should trust between perception modalities be calibrated—rules or learning?
- What’s the right balance between success and failure examples for training?
- Is atomic failure recording enough, or do some mistakes only make sense at the sequence level?
- When confidence is low, should the UI allow human intervention?
What Milestone 1 Actually Produced
No trained policies yet. No autonomy.
But the infrastructure is in place:
- multi-modal perception with provenance
- containerized browser automation with real process isolation
- session persistence with validation
- validated invoice extraction
- explicit failure recording
- live visibility into agent decisions
Next step: preference learning on navigation traces, followed by accounting-specific reasoning and human-in-the-loop flows.
Milestone 1 of 6 · January 2026