
Introduction: Why Graph RAG for Investment Intelligence?
In today's data-driven financial landscape, deriving actionable intelligence requires moving beyond siloed datasets and simple keyword searches. Investment professionals need to answer complex, multi-faceted questions that often depend on understanding the intricate relationships between companies, market events, financial instruments, and news sentiment. This is where Retrieval Augmented Generation (RAG), supercharged by Knowledge Graphs (KGs), offers a transformative approach.
The Power of Graph RAG
A Knowledge Graph represents data as a network of entities (e.g., companies, investors, news articles) and the rich relationships connecting them. When combined with Large Language Models (LLMs), this "Graph RAG" architecture enables:
- Answering Complex, Multi-Hop Questions: Traversing multiple layers of relationships to uncover non-obvious connections
- Integrating Diverse Data Types: Seamlessly linking structured financial data (like P/E ratios) with unstructured text (news articles, company summaries)
- Enhanced LLM Context: Providing LLMs with precise, relevant, and interconnected information, leading to more accurate and insightful answers than traditional vector RAG alone
- Explainable AI: The graph structure makes it easier to trace the "reasoning" path of an AI system
Technical Challenges We'll Address
This post provides a technical walkthrough of building an "Investment Intelligence KG" using Neo4j, enriching it with OpenAI LLMs, and implementing advanced Graph RAG techniques. We'll tackle:
- Consolidating siloed financial data into a connected KG
- Formulating and executing multi-hop queries that span different entities and relationships
- Leveraging LLMs for data enrichment (sentiment analysis, summarization) and natural language understanding (Text2Cypher)
- Implementing semantic search capabilities directly on the graph data
- Strategically choosing the right retrieval mechanism for a given query
System Architecture: Building an Investment Intelligence Graph RAG
The system involves several key stages, from data ingestion to sophisticated query processing.
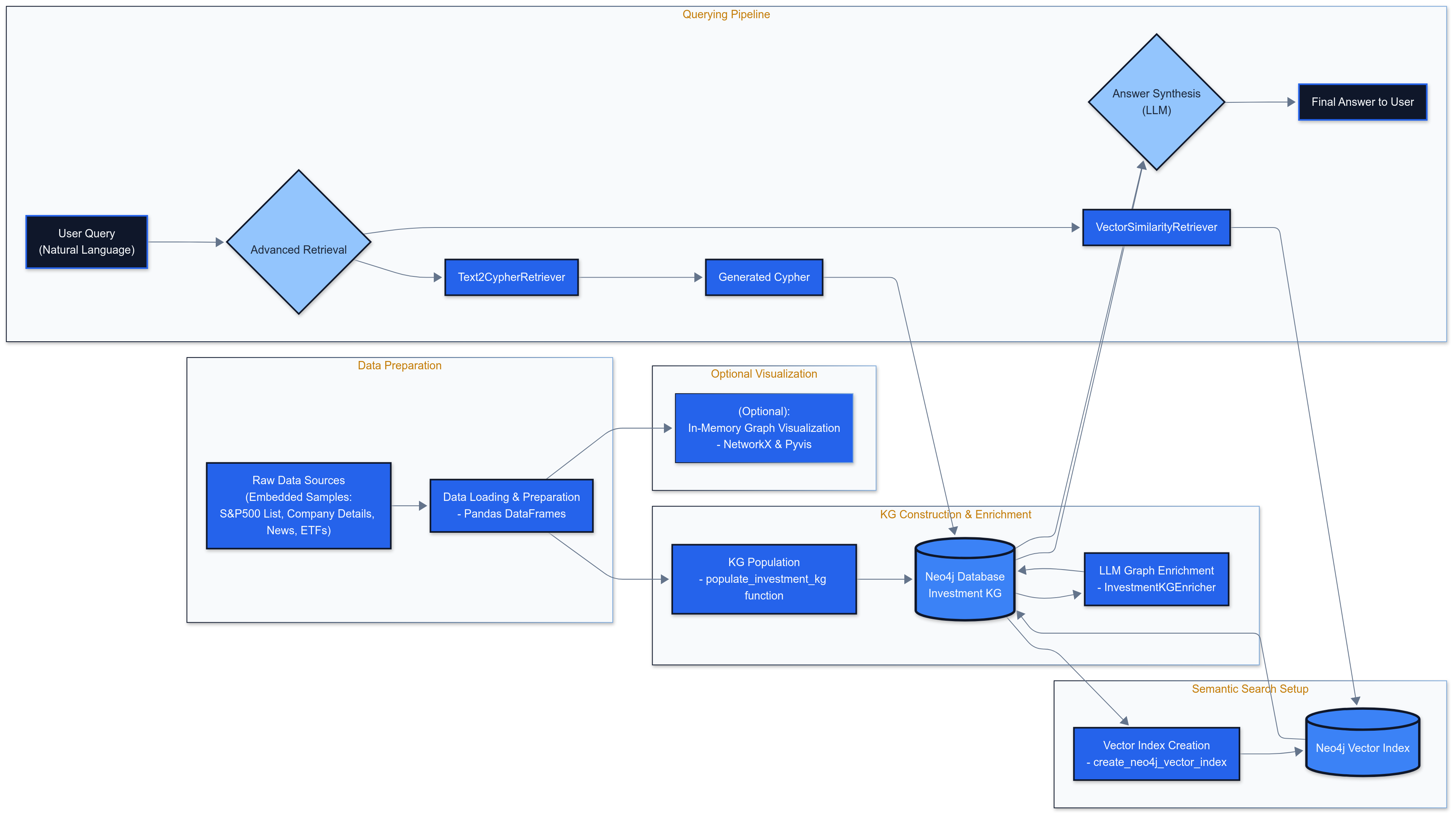
Description: This diagram illustrate the end-to-end flow:
- Data Sources (e.g., yfinance, news APIs, company filings, ETF data providers)
- ETL (Extract, Transform, Load) pipeline populating the Neo4j Knowledge Graph
- LLM Enrichment (sentiment, summaries) module interacting with the KG
- Neo4j Vector Index creation and updating
- User Query Interface
- (Conceptual) Query Router
- Text2Cypher Retriever and Vector Similarity Retriever modules
- LLM for final answer synthesis from retrieved context
- User receiving the answer
Building the Investment Knowledge Graph in Neo4j
Schema Definition
Our Investment KG comprises the following entities and relationships:
Entities (Nodes)
- Company: `ticker` (unique), `name`, `sector`, `industry`, `country`, `summary`, `marketCap`, `trailingPE`, `forwardPE`, `beta`, `website`, `recommendationKey`, `earningsDate`, `investmentProfileSummary`
- ETF: `ticker` (unique), `name`, `investmentFocus`, `assetClass`, `family`, `expenseRatio`, `AUM`
- NewsArticle: `link` (unique), `title`, `publisher`, `publishTime`, `inferredSentiment`
- Sector: `name` (unique)
- Industry: `name` (unique)
- AssetClass: `name` (unique)
- Investor: `investorId` (unique), `name`, `type`, `focus_areas`
- *\*Entity\**: A generic label for all primary entities to allow unified vector indexing
Relationships
- `(Company)-[:OPERATES_IN_SECTOR]->(Sector)`
- `(Company)-[:OPERATES_IN_INDUSTRY]->(Industry)`
- `(Company)-[:MENTIONED_IN_NEWS]->(NewsArticle)`
- `(ETF)-[:HOLDS_STOCK]->(Company)`
- `(Investor)-[:INVESTED_IN]->(Company)` with `stage` property
- `(ETF)-[:FOCUSES_ON_ASSET_CLASS]->(AssetClass)`
Implementation: Constraints and Data Population
Unique constraints are crucial for data integrity and query performance:
1def create_investment_kg_constraints_updated(driver):
2 """Creates unique constraints on node properties."""
3 if not driver:
4 logging.error("Neo4j driver not available. Skipping constraint creation.")
5 return
6
7 try:
8 with driver.session(database="neo4j") as session:
9 constraints = [
10 "CREATE CONSTRAINT IF NOT EXISTS FOR (c:Company) REQUIRE c.ticker IS UNIQUE",
11 "CREATE CONSTRAINT IF NOT EXISTS FOR (e:ETF) REQUIRE e.ticker IS UNIQUE",
12 "CREATE CONSTRAINT IF NOT EXISTS FOR (n:NewsArticle) REQUIRE n.link IS UNIQUE",
13 "CREATE CONSTRAINT IF NOT EXISTS FOR (sec:Sector) REQUIRE sec.name IS UNIQUE",
14 "CREATE CONSTRAINT IF NOT EXISTS FOR (ind:Industry) REQUIRE ind.name IS UNIQUE",
15 "CREATE CONSTRAINT IF NOT EXISTS FOR (ac:AssetClass) REQUIRE ac.name IS UNIQUE",
16 "CREATE CONSTRAINT IF NOT EXISTS FOR (inv:Investor) REQUIRE inv.investorId IS UNIQUE",
17 "CREATE CONSTRAINT IF NOT EXISTS FOR (ent:__Entity__) REQUIRE ent.name IS UNIQUE"
18 ]
19 for constraint in constraints:
20 session.run(constraint)
21 logging.info("✅ Investment KG constraints created/ensured.")
22 except Exception as e:
23 logging.error(f"🛑 Error creating Investment KG constraints: {e}")
24Example Cypher for populating the graph:
1// For Company
2MERGE (c:Company {ticker: $props.ticker})
3SET c = $props
4WITH c
5CALL apoc.create.addLabels(c, ['__Entity__']) YIELD node
6SET node.name = $props.ticker
7RETURN distinct 'company_done';
8
9// For Sector and relationship
10MERGE (s:Sector {name: $sector_name})
11ON CREATE SET s.name = $sector_name
12WITH s
13CALL apoc.create.addLabels(s, ['__Entity__']) YIELD node AS sector_node
14MATCH (c:Company {ticker: $company_ticker})
15MERGE (c)-[:OPERATES_IN_SECTOR]->(sector_node);
16Note: The `apoc.create.addLabels` procedure requires the APOC library in Neo4j.
LLM-Powered Graph Enrichment
Raw structured data is valuable, but we can enhance our KG significantly using LLMs to infer new insights.
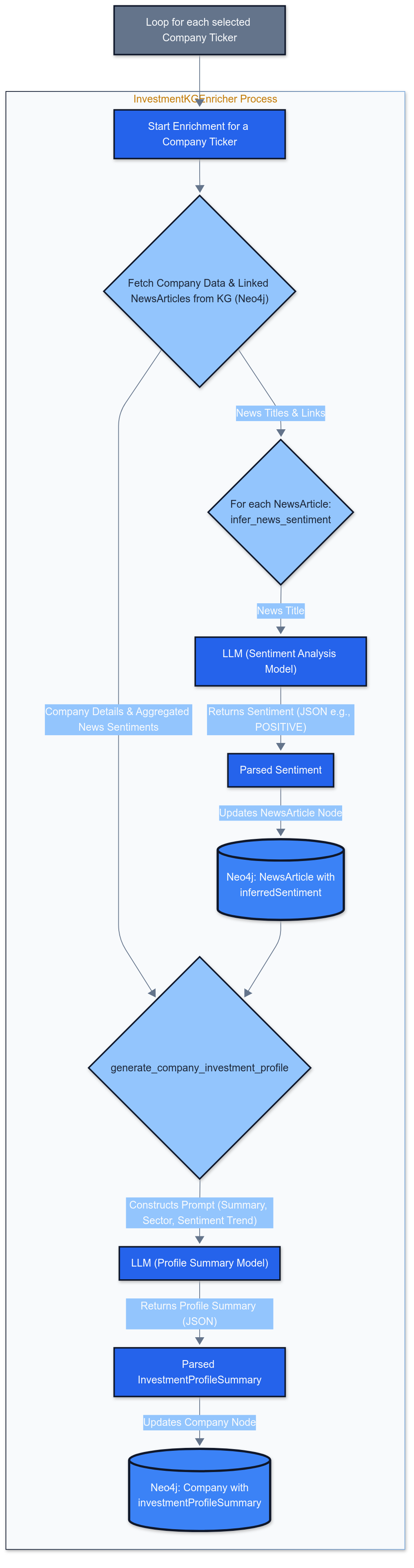
Description: This diagram shows:
- Data is read from a Company node and its related NewsArticle nodes in Neo4j
- This data is fed into an LLM (OpenAI GPT model)
- The LLM performs tasks like sentiment analysis or generates investmentProfileSummary
- Results are written back as properties on the respective nodes
Sentiment Analysis Implementation
For each NewsArticle, an LLM classifies the headline's sentiment:
1def infer_news_sentiment(self, news_article_link: str, news_title: str) -> Optional[str]:
2 prompt_messages = [
3 {
4 "role": "system",
5 "content": "You are a financial news sentiment analyzer. Classify the sentiment of the given news headline as POSITIVE, NEGATIVE, or NEUTRAL. Return ONLY a JSON object with a single key 'sentiment' and one of these three values."
6 },
7 {
8 "role": "user",
9 "content": f"News Headline: \"{news_title}\"\n\nJSON:"
10 }
11 ]
12
13 llm_response = self._get_llm_response(prompt_messages)
14
15 if llm_response and "sentiment" in llm_response:
16 sentiment = llm_response["sentiment"].upper()
17 if sentiment not in ["POSITIVE", "NEGATIVE", "NEUTRAL"]:
18 sentiment = "NEUTRAL"
19
20 # Update Neo4j
21 with self.driver.session(database="neo4j") as session:
22 session.run("""
23 MATCH (n:NewsArticle {link: $link})
24 SET n.inferredSentiment = $sentiment
25 """, link=news_article_link, sentiment=sentiment)
26
27 logging.info(f"Updated sentiment for news '{news_title[:50]}...' to {sentiment}.")
28 return sentiment
29
30 return None
31Investment Profile Generation
The LLM considers company data, sector, industry, and aggregated news sentiment to create concise profiles:
1def generate_company_investment_profile(self, company_ticker: str) -> Optional[str]:
2 # Fetch company data from Neo4j
3 # ... (query implementation)
4
5 prompt_messages = [
6 {
7 "role": "system",
8 "content": "You are a financial analyst providing concise investment profile summaries. Based on the provided company information and recent news sentiment, generate a 1-2 sentence 'investmentProfileSummary'. Focus on key characteristics, market position, or potential outlook. Output ONLY a JSON object with a single key 'investmentProfileSummary'."
9 },
10 {
11 "role": "user",
12 "content": f"""
13Company Name: {company_name}
14Sector: {sector}
15Industry: {industry}
16Existing Summary: {yfinance_summary[:1000]}
17Recent News Sentiment Trend: {overall_sentiment_hint}
18
19JSON:
20 """
21 }
22 ]
23
24 # Process and update Neo4j with the generated profile
25 # ... (implementation continues)
26Vector Indexing for Semantic Search
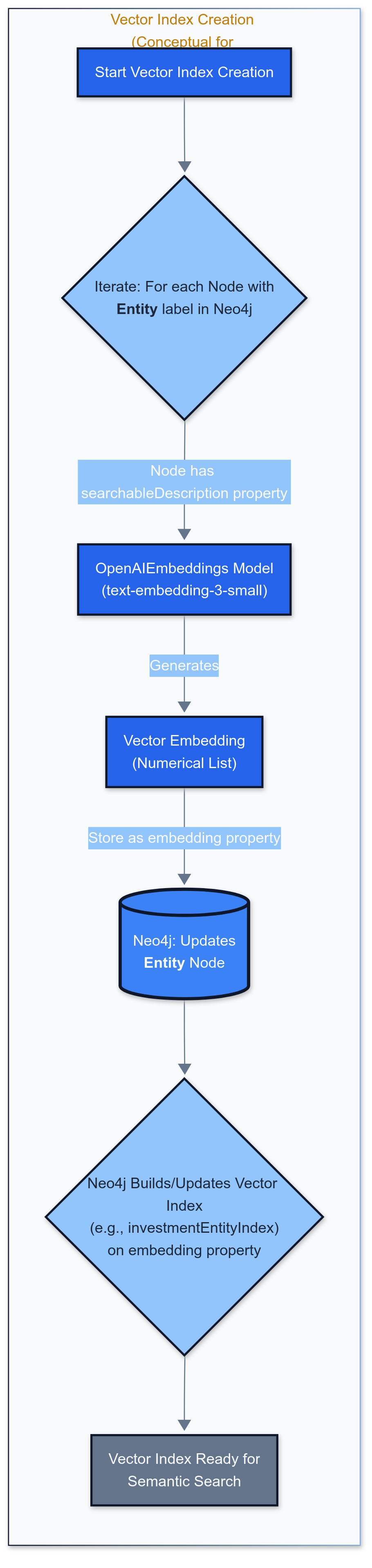
To enable querying based on conceptual meaning rather than just keywords, we implement vector indexing using OpenAI embeddings.
Creating the Vector Index
1from langchain_openai import OpenAIEmbeddings
2from langchain_community.vectorstores import Neo4jVector
3
4def create_neo4j_vector_index(driver, openai_api_key_for_lc, neo4j_uri, neo4j_username, neo4j_password):
5 embedding_node_property = 'embedding'
6 index_name = 'investmentEntityIndex'
7
8 # 1. Consolidate text into 'searchableDescription'
9 # Example for Company nodes:
10 # MATCH (c:Company)
11 # WHERE c.summary IS NOT NULL OR c.investmentProfileSummary IS NOT NULL
12 # SET c.searchableDescription = coalesce(c.name, "") + " | Industry: " +
13 # coalesce(c.industry, "") + ". Summary: " +
14 # coalesce(c.investmentProfileSummary, coalesce(c.summary, ""))
15
16 # 2. Create/Retrieve Vector Index
17 try:
18 if not os.getenv("OPENAI_API_KEY"):
19 os.environ["OPENAI_API_KEY"] = openai_api_key_for_lc
20
21 embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
22 vector_store = Neo4jVector.from_existing_graph(
23 embedding=embeddings,
24 url=neo4j_uri,
25 username=neo4j_username,
26 password=neo4j_password,
27 index_name=index_name,
28 node_label="__Entity__",
29 text_node_properties=["searchableDescription"],
30 embedding_node_property=embedding_node_property,
31 database="neo4j"
32 )
33 logging.info(f"✅ Vector index '{index_name}' created/retrieved successfully.")
34 return vector_store
35 except Exception as e:
36 logging.error(f"🛑 Failed to create/retrieve Neo4jVector index: {e}")
37 return None
38Advanced Retrieval Strategies
With the enriched KG and vector index, we can implement two powerful retrieval methods.
Text2Cypher Retriever
This retriever uses an LLM to translate natural language questions into Cypher queries.
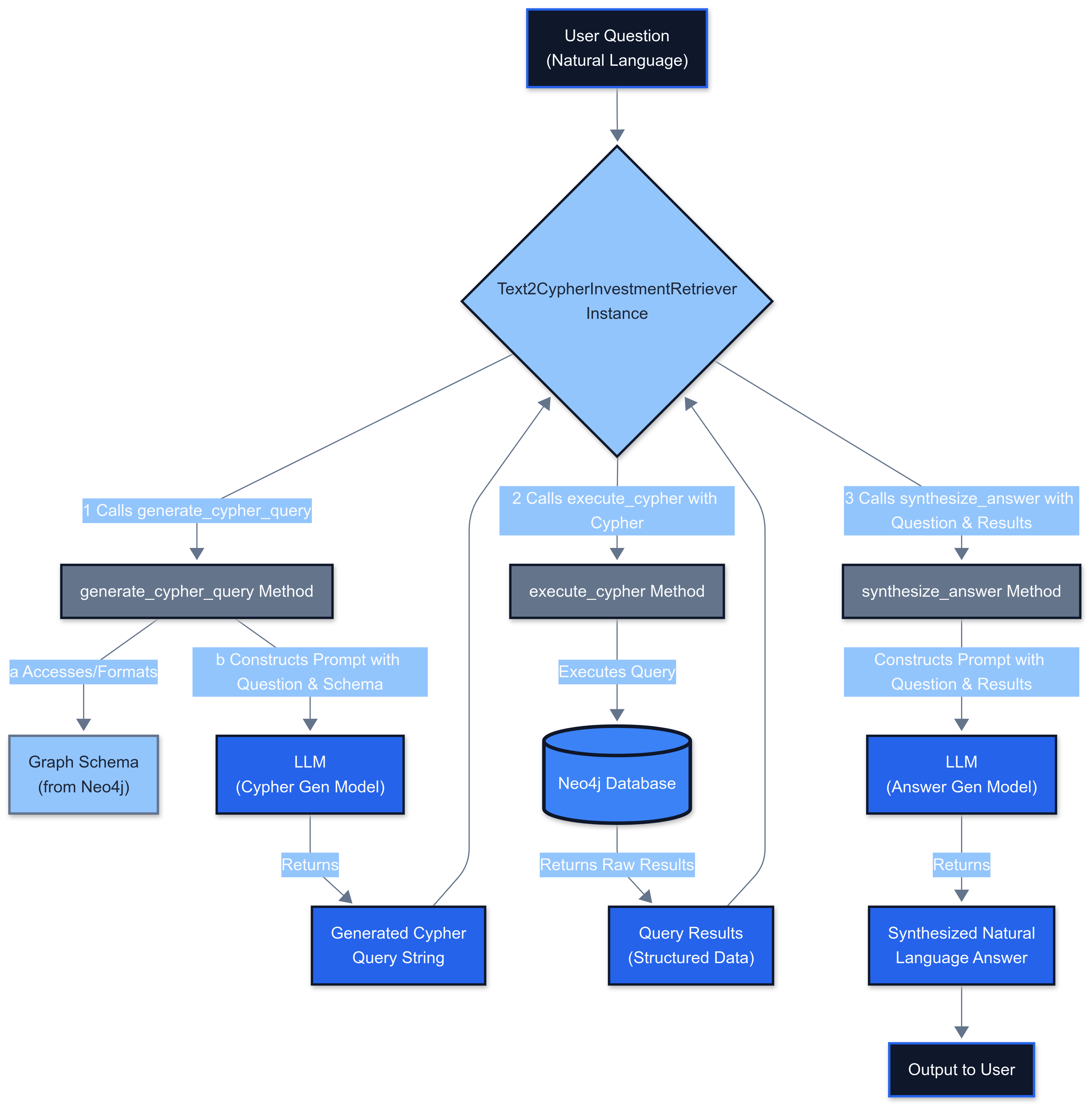
Description: This diagram shows vector similarity retriever
Core Components:
- Schema Fetching: Provides the Neo4j schema as context to the LLM
- Cypher Generation: Uses GPT-4 to generate precise Cypher queries
- Query Execution: Runs the generated Cypher against Neo4j
- Answer Synthesis: Processes results into natural language
Implementation Example:
1def generate_cypher_query(self, question: str) -> str:
2 system_prompt = f"""You are an expert Neo4j Cypher query writer...
3 Schema:
4 {self.schema}
5
6 Guidelines:
7 - Company nodes identified by 'ticker'
8 - ETF nodes identified by 'ticker'
9 - Relationships: OPERATES_IN_SECTOR, HOLDS_STOCK, INVESTED_IN (with 'stage' property)
10 - Use case-insensitive matching: toLower(node.property) CONTAINS toLower('search_term')
11 - For "latest news", ORDER BY n.publishTime DESC LIMIT 3
12 - Output ONLY the Cypher query
13 """
14
15 prompt_messages = [
16 {"role": "system", "content": system_prompt},
17 {"role": "user", "content": f"Natural language question: \"{question}\"\n\nCypher Query:"}
18 ]
19
20 # Generate Cypher using LLM
21 # ... (implementation)
22Vector Similarity Retriever
This retriever finds nodes semantically similar to a query using the vector index.
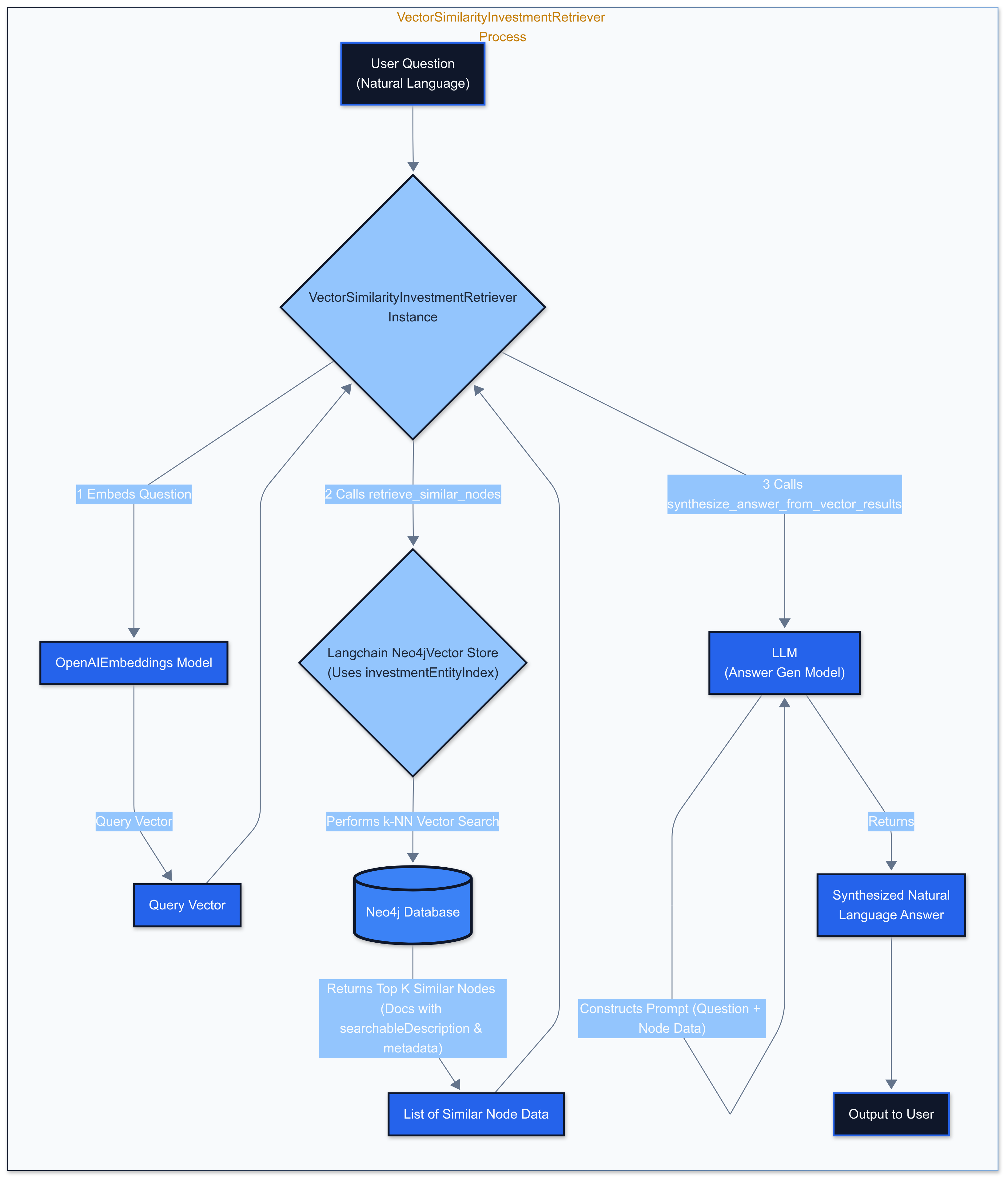
Description: This diagram shows vector similarity retriever
Implementation:
1def retrieve_similar_nodes(self, query_text: str, k: int = 5, score_threshold: Optional[float] = None) -> List[Dict[str, Any]]:
2 logging.info(f"Performing vector similarity search for: '{query_text}' (k={k})")
3
4 # Uses self.vector_store.similarity_search_with_score
5 # Returns processed results with similarity scores
6 # ... (implementation)
7
8def synthesize_answer_from_vector_results(self, question: str, similar_nodes: List[Dict[str, Any]]) -> str:
9 prompt_messages = [
10 {
11 "role": "system",
12 "content": "You are a financial analyst assistant. Based on the user's question and the semantically similar entities retrieved from a knowledge graph, provide a concise and relevant natural language answer."
13 },
14 # ... (user prompt with question and context)
15 ]
16
17 # Generate answer using LLM
18 # ... (implementation)
19The Router Retriever (Conceptual)
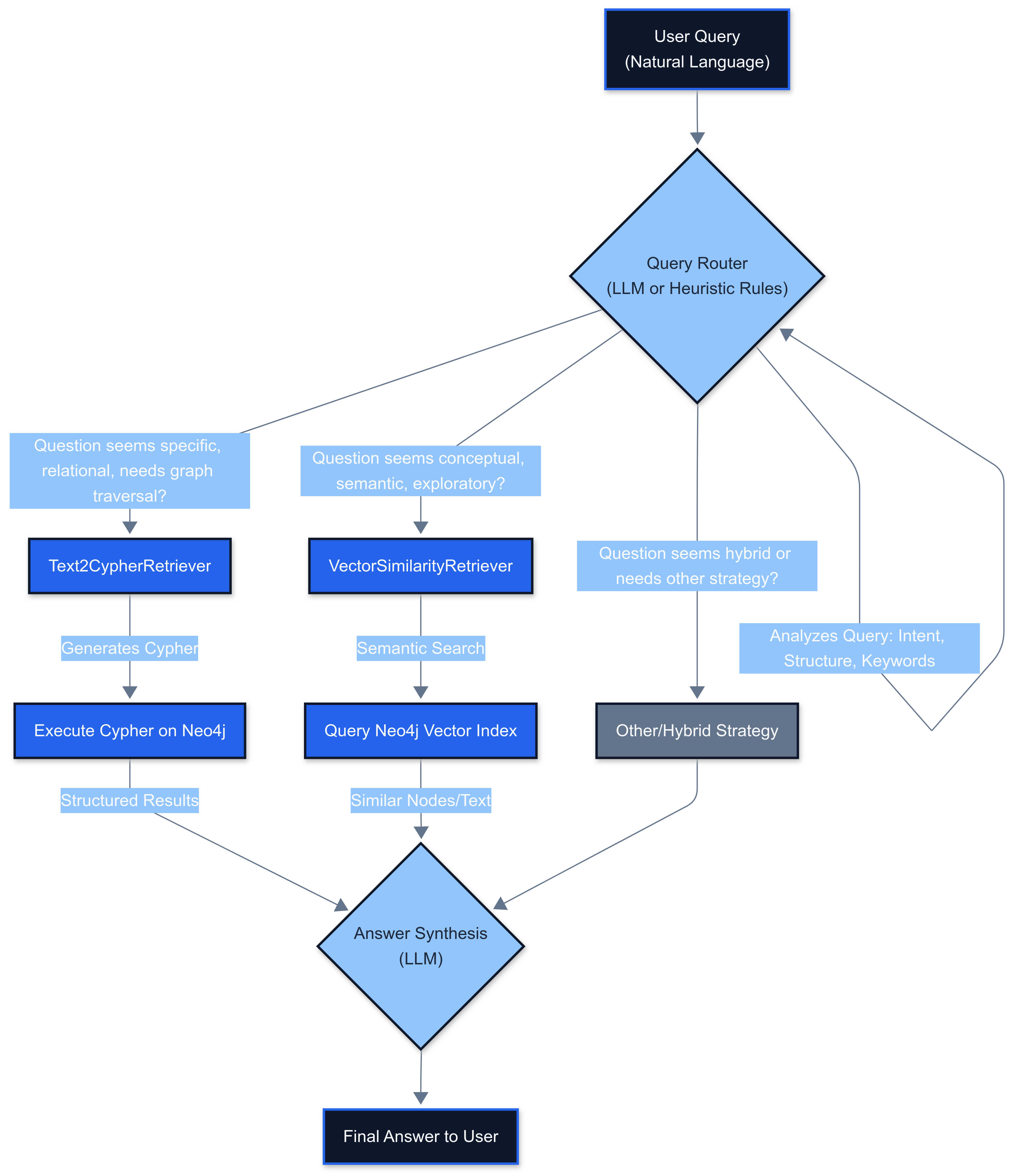
In a production system, a router would analyze incoming queries to select the most appropriate retrieval method:
- Text2Cypher: For precise, structural questions requiring exact relationships
- Vector Similarity: For conceptual, exploratory questions requiring semantic understanding
Performance, Scalability, and Best Practices
Performance Considerations
- KG Query Optimization
- Well-defined schemas and indexes on properties like `ticker` and `name`
- Cypher query optimization for complex traversals
- Connection pooling for database interactions
- Vector Index Performance
- Neo4j's native vector index performance depends on dataset size and hardware
- Consider dedicated vector databases for very large
- scale deployments
- Batch processing for embedding generation
- LLM Call Optimization
- Implement retries with exponential backoff
- Consider batching for enrichment tasks
- Cache LLM responses for identical inputs where appropriate
Common Implementation Pitfalls
- Schema Rigidity vs. Flexibility: Design schemas that can evolve with requirements
- Prompt Engineering Debt: Version control prompts and maintain prompt libraries
- Embedding Drift: Plan for periodic recomputation of embeddings
- Cost Management: Monitor LLM API usage with budget alerts
- Cypher Query Quality: Validate and log all generated Cypher queries
- Data Freshness: Implement robust ETL pipelines for continuous updates
Testing and Debugging Strategies
- Unit Testing
- Mock LLM calls and Neo4j interactions
- Test individual components in isolation
- Integration Testing
- KG validation queries for data integrity
- End-to-end retrieval testing
- Evaluation Metrics
- Text2Cypher: Query generation accuracy, execution success rate
- Vector Search: Precision@k, Recall@k, NDCG@k
- Answer Quality: Faithfulness, relevance, completeness
- Comprehensive Logging
- Log all LLM inputs/outputs
- Track generated Cypher queries
- Monitor query execution times
CI/CD and Versioning
- Data Pipelines: Version control ETL scripts
- LLM Prompts: Treat prompts as code with proper versioning
- Model Management: Track model versions and their performance
- Schema Migrations: Use tools like Neo4j migrations for schema changes
- Automated Testing: Include RAG component testing in CI/CD pipelines
Graph RAG vs. Vector RAG: When to Use Which?
Graph RAG Excels At:
- Multi-Hop Relational Queries
- Example: "Which ETFs hold both Apple and Microsoft and have an ESG focus?"
- Advantage: High precision via explicit relationship traversal
- Discovering Non-Obvious Connections
- Example: "Common investors between NVIDIA and other AI companies with positive sentiment?"
- Advantage: Uncovers complex, indirect relationships
- Conceptual Search + Structured Filtering
- Example: "Find innovative healthcare companies with high forward P/E and focus on personalized medicine"
- Advantage: Combines semantic and structured criteria effectively
Vector RAG Is Better For:
- Exploratory searches without specific structural requirements
- Content-based similarity matching
- Quick semantic retrieval without complex relationships
Infrastructure and Monitoring
Infrastructure Options
Neo4j Deployment
- Cloud (AuraDB): Managed service with automatic scaling and backups
- Self-Managed: Greater control but requires expertise in clustering and tuning
Resource Requirements
- Neo4j: Memory-intensive for graph operations, adequate disk for storage
- LLM APIs: Network bandwidth, API rate limits consideration
- Application Layer: Standard compute resources for RAG pipeline
Technical Monitoring and Observability
- Neo4j Monitoring
- Query performance metrics
- Transaction logs
- Cluster health monitoring
- Tools: Neo4j Browser, Prometheus exporters
- LLM API Monitoring
- API call latency and error rates
- Token consumption tracking
- Cost monitoring
- Tools: OpenAI dashboard, LangSmith, Helicone
- Application-Level Observability
- Detailed logging for each RAG stage
- Distributed tracing for complex chains
- User feedback mechanisms
- Tools: Jaeger, OpenTelemetry
Conclusion: Building ROI-Driven AI with Graph RAG
Combining Knowledge Graphs with LLM-driven RAG techniques provides a powerful paradigm for financial investment intelligence. By structuring data as an interconnected graph and leveraging LLMs for enrichment and natural language interaction, we unlock deeper insights and answer complex, multi-hop questions with greater precision than traditional methods.
Key Technical Recommendations:
- Invest in Schema Design: A well-thought-out Knowledge Graph schema is fundamental
- Iterative Enrichment: Use LLMs to progressively enrich your KG with inferred properties
- Hybrid Retrieval: Combine Text2Cypher precision with vector search exploration
- Robust MLOps: Manage prompts as code, monitor performance and costs
- Focus on Verifiability: Graph RAG enables tracing answer derivation, crucial for finance
The journey from siloed data to actionable intelligence is complex but highly rewarding. Graph RAG, by embracing the connected nature of data, offers a significant step forward in building next-generation AI-powered financial applications.
If you're an engineering leader or ML engineer looking to architect and implement advanced AI solutions like Graph RAG to solve specific business challenges in finance or other complex domains, I offer AI engineering consulting services. I specialize in moving AI projects from proof-of-concept to robust, scalable, and ROI-driven production systems. Let's discuss how we can transform your data into strategic intelligence.
💻 Explore the Code & Go Deeper!
All the concepts, detailed code examples, and the foundational Jupyter Notebook discussed in this blog post are available in our public GitHub repository. This is your opportunity to:
- Get Hands-On: Clone the repository to run the code, experiment with the graph database setup, and test the retrieval mechanisms yourself.
- Examine the Implementation: Dive into the specifics of the data enrichment pipeline, vector index creation, and the Text2Cypher/Vector Search retriever classes.
- Adapt and Innovate: Use this project as a launchpad for your own advanced RAG solutions in investment intelligence or other domains.
➡️ Access the Full Project on GitHub: Advanced Graph RAG for Investment Intelligence
We encourage you to star the repository if you find it useful, and contributions or feedback are always welcome!
If you're an engineering leader or ML engineer looking to architect and implement advanced AI solutions like Graph RAG to solve specific business challenges in finance or other complex domains, I offer AI engineering consulting services. I specialize in moving AI projects from proof-of-concept to robust, scalable, and ROI-driven production systems. Let's discuss how we can transform your data into strategic intelligence. *(Connect with me: LinkedIn | Book a Consultation)*
Additional Resources and References
Tools and Libraries
- Neo4j Graph Database: The leading graph database platform
- OpenAI API: For GPT-4 and embedding models
- LangChain: Framework for developing applications powered by language models
- APOC (Awesome Procedures on Cypher): Extended library for Neo4j
- yfinance: Python library for accessing financial data
Documentation and Guides
- Neo4j Documentation: Comprehensive guide to Neo4j
- Cypher Query Language: Complete Cypher reference
- OpenAI Embeddings Guide: Best practices for embeddings
- LangChain Vector Stores: Vector store integrations
Research Papers and Articles
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks: Original RAG paper
- Knowledge Graphs: Comprehensive survey of knowledge graphs
- Graph Neural Networks: A Review of Methods and Applications: GNN overview
Community Resources
- Neo4j Community Forum: Active community for Neo4j questions
- OpenAI Developer Forum: OpenAI API discussions
Advanced Topics for Further Exploration
- Graph neural networks for financial predictions
- Multi-modal RAG systems incorporating images and documents
- Real-time graph updates and streaming architectures
- Federated learning for privacy-preserving financial AI
- GraphQL integration with Neo4j for flexible API development