
The Problem: The Confident Liar
As engineers, we often treat Large Language Models (LLMs) as opaque inference engines: a prompt enters, text exits, and we evaluate the output based on surface-level correctness.
While exploring model failure modes, fabricated citations emerged as a particularly sharp example that standard evaluation metrics failed to capture.
The model would invent a case—Harrison v. McDonald—and cite it with the precise formatting and tonal confidence of a Supreme Court opinion. The issue wasn't just that the output was factually wrong; it was that the model's internal confidence appeared indistinguishable from when it cited real case law.
I wanted to move beyond "prompt engineering" to answer a fundamental question: Can we detect the difference between retrieved knowledge and stochastic pattern matching by observing the model's internal activations?
This post documents the engineering journey including the failed hypotheses and broken code required to differentiate "memory" from "imagination" inside a transformer.
Phase 1: First Principles & The "Logit Lens"
Transformers operate on a residual stream, where information accumulates across layers. My working hypothesis was based on two distinct behaviors:
- Grounded Recall: If a model "knows" a fact (e.g., *Paris is the capital of France*), the concept should emerge gradually as the layers process.
- Ungrounded Fabrication: If a model is hallucinating, it is likely executing a syntax-completion subroutine (e.g., `[Plaintiff] v. [Defendant]`) and selecting names at the final layer based on probabilistic fit rather than semantic binding.
Using the Logit Lens technique on GPT-2, I visualized this difference.
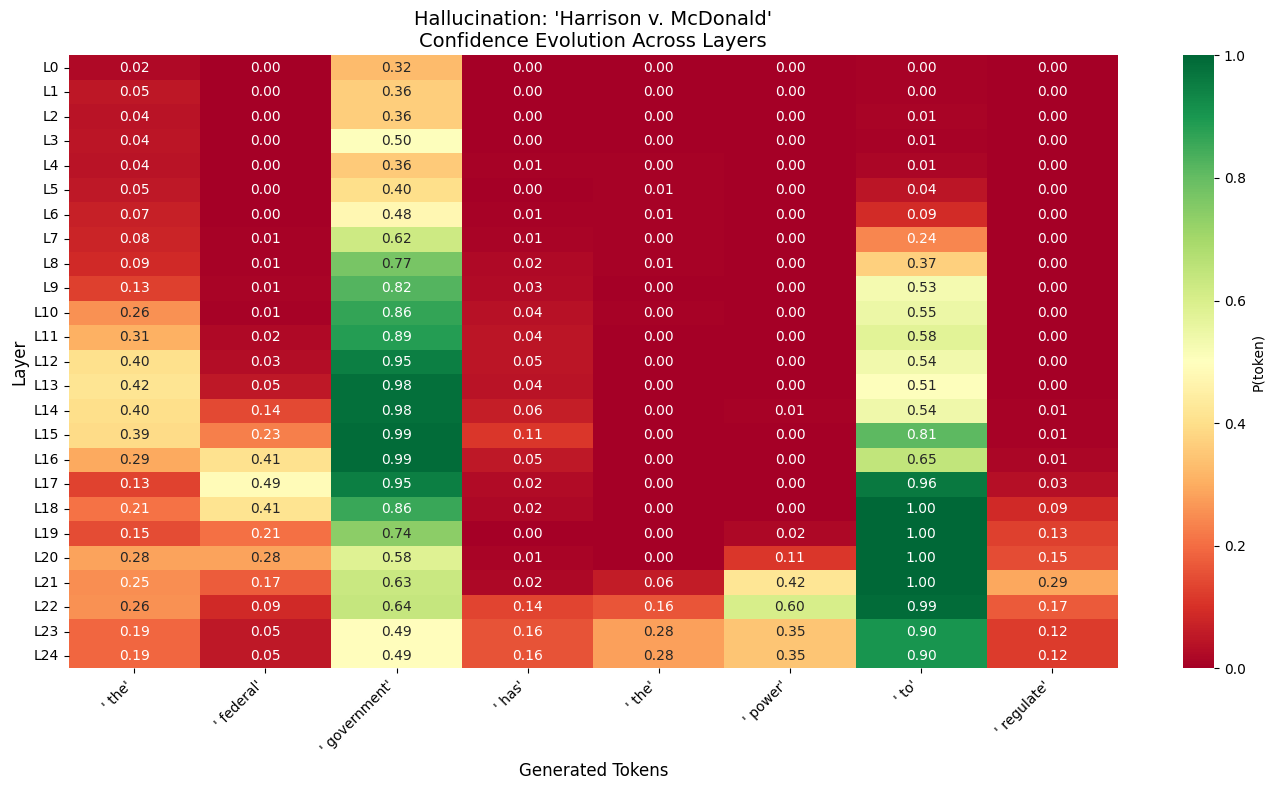
- The Fact: The token "Paris" stabilized in the mid-to-late layers and remained stable.
- The Lie: The tokens for the fabricated text remained low-confidence until the final layers, where they suddenly spiked.
Phase 2: The "Topic Drift" Discovery
To verify this wasn't a visual artifact, I ran a Noise Injection experiment (similar to *Rome et al.*). I injected high-magnitude Gaussian noise (σ=2.0) into intermediate layers to see how fragile the information was.
The difference in failure modes was visible in the raw console logs.
Factual Prompt: ("The capital of France is...")
When I corrupted Layer 8, the model performed an Entity Swap.
1Input: ...capital of France is
2Output: ...capital of the United States
3The model preserved the structure (Country → Capital) but lost the instance. It "forgot" France but still knew it was talking about geopolitics.
Hallucinated Prompt: ("The case of Harrison v. McDonald...")
When I applied the same noise to the fake citation, the model didn't swap names. It experienced Topic Drift.
1Input: ...case of Harrison v. McDonald
2Output: ...principles of equal protection and privacy
3The model completely lost the plot. It drifted from "validity" to "privacy" to "equal protection". This suggests that the hallucination failed to maintain a stable intermediate representation; it was a transient surface pattern generated during late-stage completion.
Phase 3: The Logic Error (The Naive Heuristic)
Armed with this insight, I built my first detector. I assumed a sudden "Confidence Spike" in the final layer was the unique signature of a lie.
The Failure: My detector began flagging real facts as hallucinations.
Looking back at my initial code, the bug is obvious. I was calculating risk by subtracting the spike size, effectively rewarding the model for spiking:
1# ❌ The Logic Bug: Rewarding the spike
2raw_score = w_low_late * (1.0 - late_conf) - w_spike * spike
3The discriminative signal wasn't the spike itself—both facts and hallucinations spike when the model "commits" to an answer. The real signal is the interaction between early entropy and late confidence.
The Corrected Signal (one effective formulation):
1# ✅ The Fix: Early entropy × Late confidence interaction
2# High early entropy = model was confused in mid-layers
3# High late confidence = model committed anyway (syntactic completion)
4hallucination_score = early_entropy * late_confidence
5A model that is confident at the end, but was confused in the middle, is likely hallucinating.
The token-level signal was noisy and prompt-dependent, which is why I moved to span-level aggregation and statistical validation across 60+ prompts.
Phase 4: Validation & Ablation
To prove this, I ran an Ablation Study. I systematically disabled features to see which ones contributed to the separation between Real and Fake citations.
| **Configuration** | **Fake Risk** | **Real Risk** | **Delta** |
|---|---|---|---|
| **Full Model** | 0.426 | 0.403 | +0.022 |
| Confidence Only | 0.158 | 0.166 | **-0.007 (Inverted!)** |
| Early Entropy Only | 0.069 | 0.059 | +0.010 (Weak) |
| **Conf + Entropy** | 0.216 | 0.200 | **+0.016 ** |
The key insight is directional: Confidence alone is inverted it would flag real facts as hallucinations, confirming the Phase 3 bug.
The signal emerges from the interaction of early entropy and late confidence. Although early entropy alone shows a positive delta, its effect size is small and unstable across prompts, making it insufficient as a standalone signal.
Phase 5: Scaling to Llama-3 (The Reality Check)
In my initial notebook, the detector achieved strong separation on a small test set (n=10). Before claiming victory, I expanded the test suite.
The Humbling: When I scaled to 77 prompts on GPT-2, the signal remained significant (p=0.003)—but the effect size collapsed from Cohen's d=4.73 to d=0.73. The "perfect" separation was a small-sample illusion.
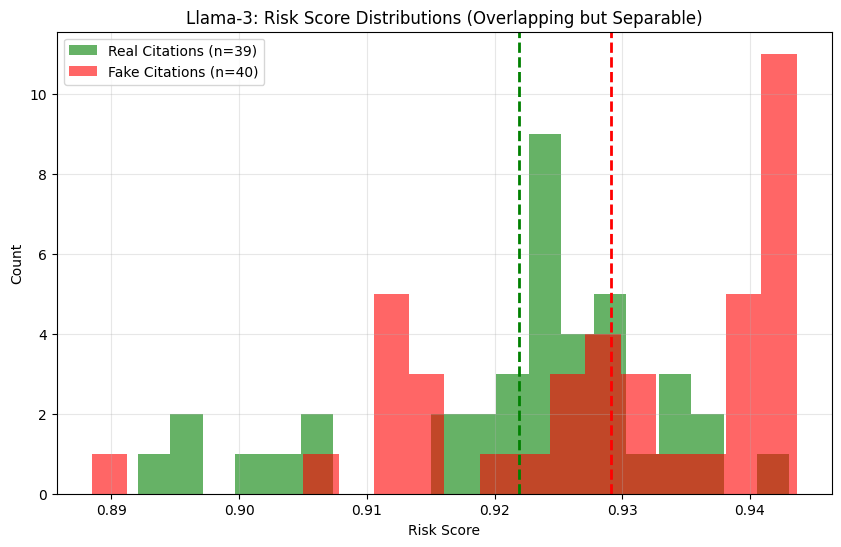
The Pivot: I ported the analysis to Llama-3-8B, a modern RLHF-tuned model, hypothesizing that models trained with human feedback might have more distinct confidence patterns.
The Result: The signal re-emerged, but it was noisy.
| Metric | GPT-2 (n=10) | GPT-2 (n=77) | Llama-3 (n=95) |
|---|---|---|---|
| AUC | - | 0.709 | **0.676** |
| p-value | 0.0040 | 0.003154 ✅ | **0.007** ✅ |
| Cohen's d | 4.7301⚠️ | 0.7321 | **0.5729** |
⚠️ *Suspiciously high — small-sample artifact*
Interpretation: Even in heavily fine-tuned models, hallucinations leave a trace. The model is statistically "more confused" in the middle layers when lying than when telling the truth. However, an AUC of 0.68 confirms that this signal is noisy ,it is not a silver bullet. The distributions of "confident truths" and "confident lies" overlap significantly. This progression illustrates how easy it is to overfit mechanistic signals on small, hand-picked sets, and why scaling and re-validation are non-negotiable.
System Design: Observability over Prevention
This finding dictated the final system architecture. If we had an AUC of 0.95, we could build a firewall that auto-blocks hallucinations. With an AUC of 0.68, blocking would flag a substantial fraction of legitimate citations.
Crucial Engineering Detail: Tokens vs. Spans
In my early experiments, I analyzed raw tokens. This was too noisy—the model might be confident about "Harrison" but confused about "v.".
I realized that a legal citation is an atomic unit of truth. I refactored the detector to aggregate token probabilities into Span-Level Risk Scores. We don't flag individual tokens; we flag semantic spans that correspond to atomic claims.
The Pivot: Instead of a "Blocker," I built an Annotator.
The system calculates the entropy signature on the fly. If the risk score crosses a threshold, we don't silence the model—we inject a visual indicator:
*"The case of Harrison v. McDonald* [?] *established…"*
This converts silent hallucinations into visible uncertainty.
Conclusion
We often talk about "Aligning" AI, but we rarely talk about giving it the tools to know when it is guessing. By looking at the internal physics of the model—specifically the entropy of the residual stream—we can start to distinguish between memory and imagination.
The journey from "Logit Lens" to "Mechanistic Observability" wasn't a straight line. It required breaking the "Confidence" heuristic, debugging the math, and accepting that mechanistic signals are probabilistic, not binary.
We didn't solve the problem of hallucinations, but we did solve the problem of silent hallucinations.
Code and Notebooks: GitHub Repo Link